








*本記事は旧TechblogからCOLORSに統合した記事です。
1.自己紹介
こんにちは、エイアイ・フィールドData Solution DepartmentのA.Sです。
前職は食品製造業で購買や経理の仕事をしていました。
また、機械学習、ディープラーニングを用いて需要予測や画像処理や自然言語処理の業務をしていました。
その中でAIの仕事を本業にしたいと思いこの会社に入社しました。
アプローチは自然言語処理と画像処理がある中、前編は自然言語処理、後編は画像処理で、顔文字を正しく分類できるか実験してみました!
2.使用する顔文字
Simejiの顔文字辞典から顔文字を一部使用させて頂きました。
https://simeji.me/blog/%E9%A1%94%E6%96%87%E5%AD%97-%E4%B8%80%E8%A6%A7/kaomoji/id=10021
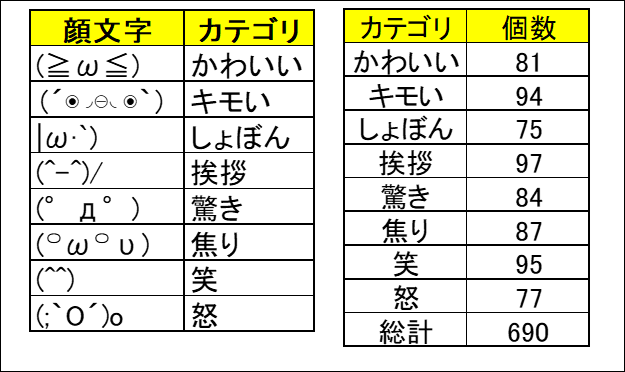
今回使用する顔文字は全部で690個です。
カテゴリはかわいい、キモい、しょぼん、挨拶、驚き、焦り、笑、怒の8種類。
自然言語処理と画像処理のAIで、この8種類をどの程度の精度で分類できるか実験していきます。
3.まずは自然言語処理で実験!!
大前提として人間が顔文字を分類しようとする時、顔文字全体を
画像として捉えて笑っているとか怒っていると判断しますよね。
なので、文字(自然言語処理)として分類するということは、
人間からすると違和感があります。
ただ、ある特定の文字が使われていると怒に分類されやすいとか、
文字の順番から判断するということは人間でもできると思うので、
ある程度の精度が出るのではないかと推測されます。
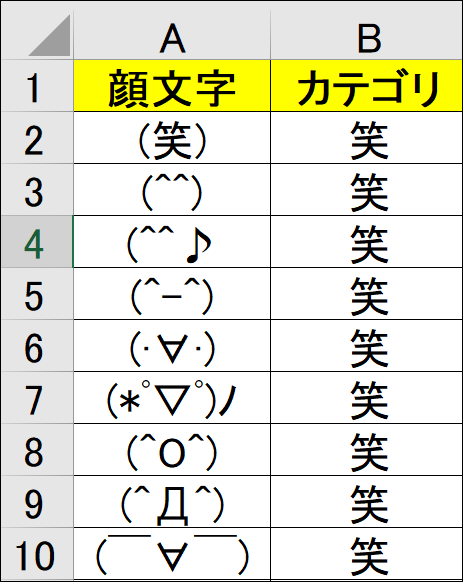
3.1 Excelに保存されている顔文字をPython上で使えるようにする
下図のような表を作り、kaomozi.xlsxのsheet1に保存しています。
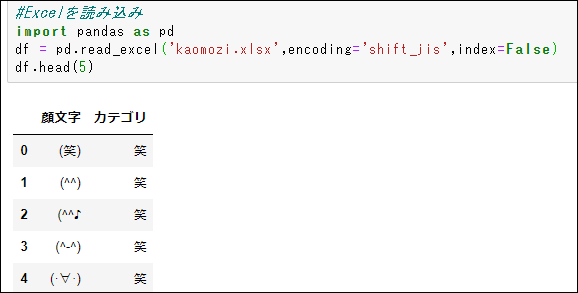
今回は、Jupyter NotebookでPythonを動かします。
ExcelからPythonのPandasに格納するコードは以下の通りです。
3.2 顔文字を1文字ずつ分解して重複のない相互辞書を作る
文字とID、IDと文字どちらからも参照できる辞書を作ります。
今回の文字の種類は703種類でした。

3.3 相互辞書を参照して顔文字をIDに変換
文字のままでは学習できないので数値化します。
先ほどの相互辞書を使用してIDに変換します。

3.4 最大文字数に達していない名前を0でパディングして反転する
学習の都合上、最大文字数(57文字)にサイズを合わせる必要があるので0でパディングします。
また、予測の時に辞書に存在しない文字も0に変換します。反転する理由は精度が高まるためです。
これで学習するための説明変数が完成しました。


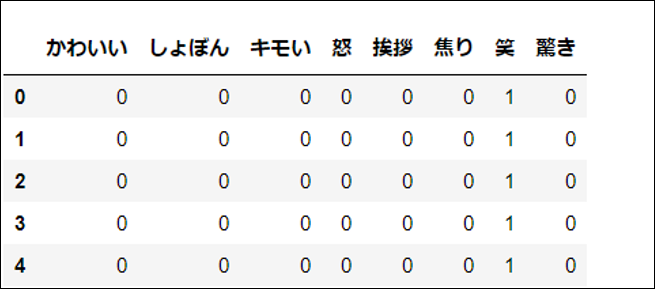
3.5 目的変数のカテゴリをOne Hot vectorに変換
カテゴリが文字列では学習できないので0か1に変換します。笑の場合は、笑が1、それ以外が0となります。
こうすることで、笑が100%、それ以外が0%という確率的な意味合いを持ち、AIが学習することができます。
ちゃんと8種類になっているのがわかります。

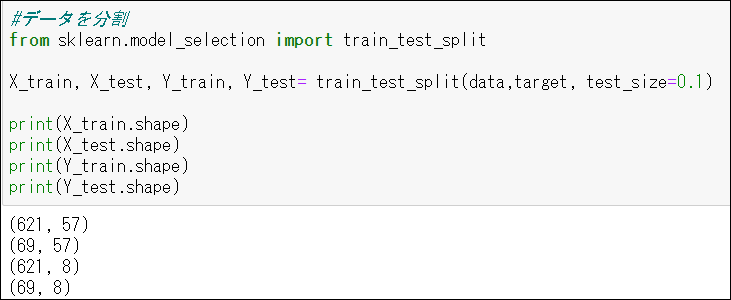
3.6 訓練データとテストデータにデータを分割(9:1)
訓練データで学習をして、テストデータで精度を確認します。
説明変数の二次元が最大文字数の57になり、目的変数の二次元がカテゴリ数の8になっていることが確認できます。
3.7 Embedding層と一次元畳み込み層を搭載したモデルで学習
3.7.1 モデルの全体像
フレームワークはkerasを使用しています。

3.7.2 Embedding層とは?
wikipediaでは、語彙からの語または句が実数のベクトルにマッピングされる
自然言語処理における言語モデリングおよび機能学習技術のセットの総称と記載されています。
少し噛み砕いて説明します。
今回のモデルの一番最初の層がEmbedding層です。まず(None,57,200)の意味を説明します。
Noneは学習する顔文字の数です。バッチサイズといいます。
57は最大文字数です。200は私が指定した次元です。
この形でベクトルが出力されるということです。
わかりやすくするために最大文字数が5。
指定した次元が6の場合のEmbeddingを出力します。

(5,6)になっています。各行が顔文字の一文字一文字を意味しています。
2文字目と4文字目が「・」ですが、同じベクトル(列)を出力しているのがわかります。このように顔文字が変換されます。
3.7.3 一次元畳み込み層とは?
画像処理の二次元畳み込み層が有名ですが、それの一次元バージョンです。
今回は、スライド3のフィルタを1024枚使用します。
また、次元が変わらないように 調整しているので最終的に(57,1024)の形で出力されます。
それを一次元のMaxpoolingにかけます。フィルター1枚1枚(57,1)の最大値を
取り、それを1024枚出力するので、(1024,1)となります。
3.7.4 モデルを学習
バッチサイズ 64で、訓練データを150周学習させました。(150epoc)
学習のcompileは下記のとおりです。

3.8 テストデータで精度確認
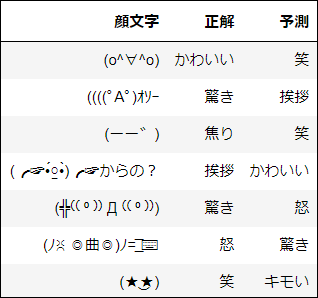
結果は約66.7%でした!!文字だけのアプローチにしては随分あてられているのではないでしょうか。ちなみにLSTMという時系列処理の王道モデルで学習するとたったの8%でした。。LSTMのほうが学習時間が膨大なのに。。画像は外してしまった顔文字の一部です。

4.まとめ
自然言語処理のAIで顔文字を66.7%の精度で分類できました。
7割近い精度に驚いています。。高くても30%くらいだと思っていたので。。
次回は画像処理のAIで実験しますのでお楽しみに!!




