








*本記事は旧TechblogからCOLORSに統合した記事です。
自己紹介
こんにちは!MS事業部 データマイニング推進部のnvmと申します。
入社前は約3年間でシステムエンジニアとして仕事をしました。入社後はSQLの研修やPythonの研修を受けて、データ分析及び機械学習のモデリングの演習を行いました。
機械学習のモデリングにあたってKaggleという世界最大規模の機械学習モデルを構築するコンペティションのプラットフォームに参加して、様々なデータの問題に対して機械学習モデルを作成、モデルのベストスコアで順位を他の参加者と競いました。
最初は慣れなかったので困ったこともありましたが、学習用のコンペ(コンペティション)を2つ練習したら慣れるようになりました。そしてKaggleのコンペに熱中して、約6ヶ月間で銅メダルを3つ獲得しました。
今回の記事では各コンペに活用したKaggleのNotebooks / Kernel機能をハンズオンの形でデータ予測モデルを構築しながら紹介したいと思います。 又、Kaggleで勉強になりました小テクニックも共有したいと思います。
本記事に使用するデータはKaggle のSantander Customer Transaction Predictionコンペティション(Santanderコンペ)のデータです。
Santanderコンペについて
Santanderコンペ はスペインの最大の商業銀行グループSantanderが主催会社であり、どのユーザーが取引を行うかを予測するコンペでした。
前提条件
・Pythonの基礎知識(Jupyter Notebook)
・機械学習モデリングの基礎知識
・Kaggleアカウント及びインターネット接続端末
本記事の構成
本記事は、前後編の2回に分けてお届けします。
・前編:シンプルで高速特徴量の選択法
・後編:効率的に前処理結果利用法 及び高機能の無料GPUでモデル構築法
目次
1.KaggleでNotebook作成
2.データの確認
・データの統計量の確認
・欠損データの確認
3.フィルター法におよる特徴量の選択
・不変説明変数を確認
・準不変の特徴量(分散がほぼ0)を確認
・重複した特徴量の確認
・相関のある特徴量の確認
1.KaggleでNotebook作成
・まずは、コンペのページにアクセスします。
https://www.kaggle.com/c/santander-customer-transaction-prediction/
・「Notebooks」タブをクリックして、「New Notebook」をクリックする
※アカウントログインが必要
・「Notebook」を選択して、「Create」をクリックします。
・Jupyter Notebookと同じような画面が表示されましたらコーディングできます。
# 必要なライブラリをインポート
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split, KFold
from sklearn.feature_selection import VarianceThreshold
from sklearn.metrics import roc_auc_score
import lightgbm as lgb
import catboost as ctb
from catboost import Pool, CatBoostClassifier
import time
import gcインプットデータファイルは “../input/” フォルダにあります。
下記ソースコードを実行して確認することができます。
import os
print(os.listdir("../input"))['sample_submission.csv', 'santander-customer-transaction-prediction.zip',
'target.feather', 'test.csv', 'test_extra_features.feather', 'test_ids_extra_features.feather',
'train.csv', 'train_extra_features.feather', 'train_ids_features.feather']
2.データの確認
df_train = pd.read_csv("../input/train.csv")
df_test = pd.read_csv("../input/test.csv")
print("Trainデータのディメンション:",df_train.shape)
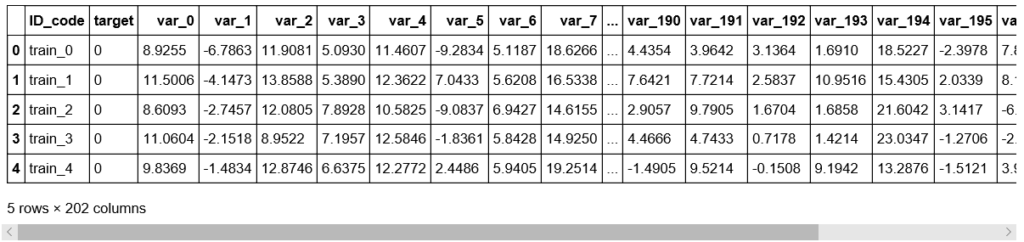
print("Trainデータのサンプル:")
df_train.head()Trainデータのディメンション: (200000, 202)
Trainデータのサンプル:
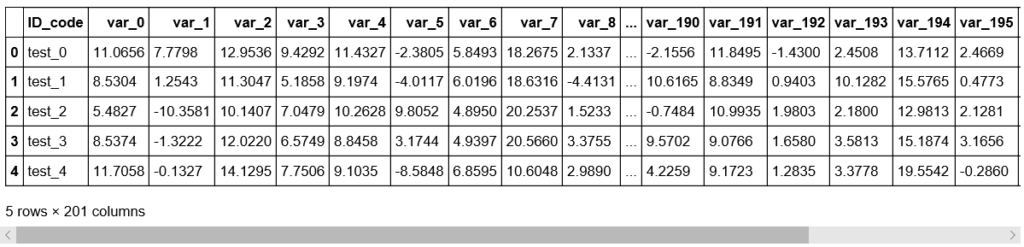
print("Testデータのディメンション:",df_test.shape)
print("Testデータのサンプル:")
df_test.head()Testデータのディメンション: (200000, 201)
Testデータのサンプル:
データの統計量の確認
df_train.describe()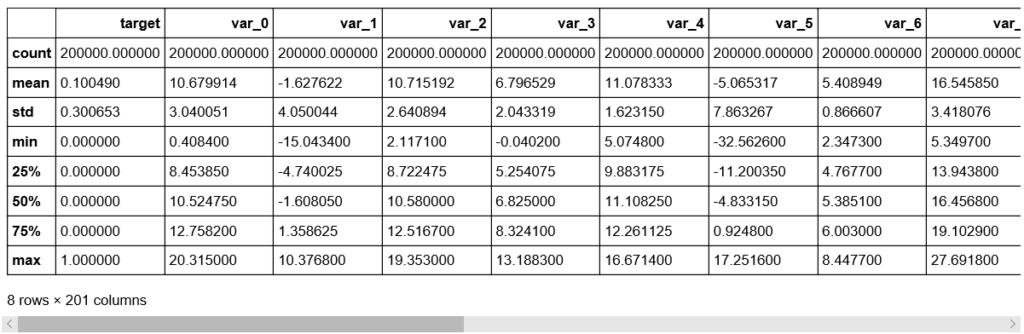
df_test.describe()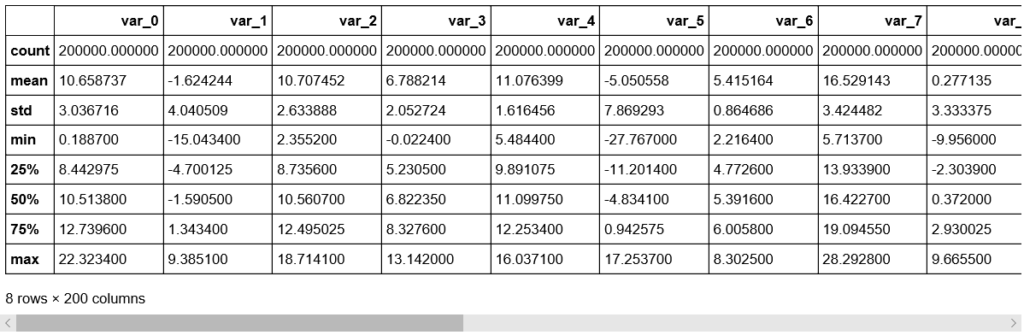
・標準偏差は、TrainデータとTest変数データの両方に対して比較的大きい。データが平均値から広がっている。
・TrainデータとTestデータの最小値、最大値、平均値、標準偏差値は非常に近い。
・平均値は広範囲に分布している。
欠損データの確認
・これはデータ分析の最も重要なステップの一つだと言われます。データ内の欠損値の確認結果によって、そのデータに対する処理方法は違います。
・欠損値が適切に処理されない場合、データについて不正確な推論を引き出すことになるかもしれません。
では、欠損データがあるかどうかを確認しましょう。
def missing_value(df):
mis_val_sum = df.isnull().sum()
mis_val_percent = 100 * df.isnull().sum() / len(df)
df_mis_val = pd.DataFrame({'Missing Values': mis_val_sum,'% of Total Values': mis_val_percent})
return np.transpose(df_mis_val)
missing_value(df_train)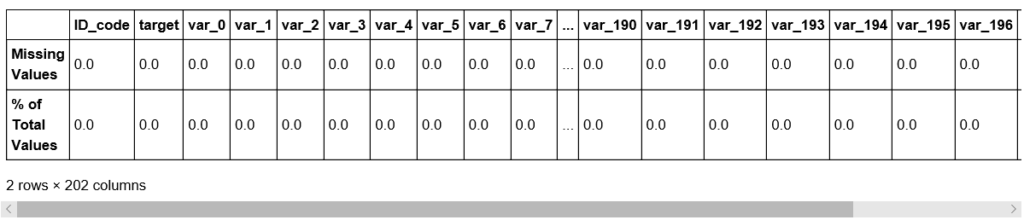
missing_value(df_test)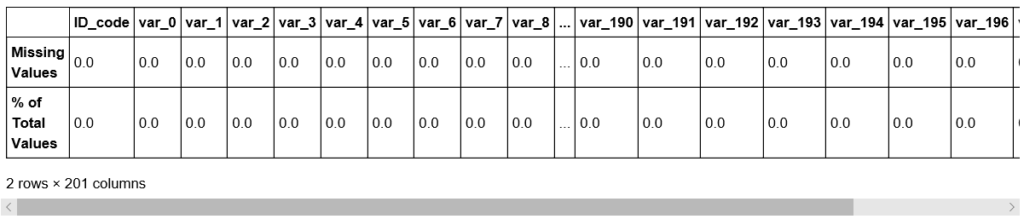
・TrainデータとTestデータに欠損データが存在しない。
Trainデータの項目構成:
・ID_code(文字列)
・target(目的変数)
・var_0からvar_199まで(説明変数 – 数値型)
Testデータの項目構成:
・ID_code(文字列)
・var_0からvar_199まで(説明変数 – 数値型)
3.フィルター法におよる特徴量の選択
参考:Lead Data Scientist - Soledad GalliさんのUdemy口座を参考にしています。 Feature Selection for Machine Learning
特徴量選択(Feature Selection)によって以下の効果があると期待されます:
・モデルの精度が向上する。
・モデルの複雑さが軽減され、簡単に解釈できるようになる。
・学習時間を減らせる。
・過学習を減らせる。
・ソフトウェア開発者による実装が容易。
・モデル使用中のデータエラーのリスクを軽減。
特徴量選択の種類は主に3種類があります:
・フィルター法( Filter Method )
・ラッパー法(Wrapper Method)
・埋め込み法( Emedded Method )
今回は一番簡単であるフィルター法でデータの特徴量の選択を行って行きます。
フィルター方法( Filter Method )の概要:
・データの特徴に頼る。
・機械学習アルゴリズムを使わない。
・計算量が少なくなる傾向がある。
・クイックスクリーンや関係のない特徴量の削除に非常に役立つ。
フィルター法を適用して、特徴量選択を行っていきます。
不変説明変数を確認
不変説明変数が存在する際に削除します。
X_train = df_train.drop(labels=['ID_code', 'target'], axis=1)
y_train = df_train['target']
X_test = df_test.drop(labels=['ID_code'], axis=1)# 不変説明変数リストを取得
constant_features = [
feat for feat in X_train.columns if X_train[feat].std() == 0
]
# 不変説明変数リストを表示
constant_features[]
不変説明変数が存在しない。
準不変の特徴量(分散がほぼ0)を確認
特徴量の値の大部分が同じデータであるかどうか確認します。
# 準不変特徴量を削除
sel = VarianceThreshold(threshold=0.01) # 0.01 観測値の約99%を示す。
sel.fit(X_train) # fitは、分散が小さい特徴を見つけます。
# 準不変特徴量ではないものはいくつあるか。
sum(sel.get_support()) 199
全て特徴量は準不変特徴量ではない。
重複した特徴量の確認
%%time
# トレーニングセット内の重複した特徴量を確認
duplicated_feat = []
for i in range(0, len(X_train.columns)):
col_1 = X_train.columns[i]
for col_2 in X_train.columns[i + 1:]:
if X_train[col_1].equals(X_train[col_2]):
duplicated_feat.append(col_2)
len(duplicated_feat)Wall time: 4min 13s
重複した特徴量が存在しない。
相関のある特徴量の確認
%%time
# 相関のある特徴量を見つけて削除する
def correlation(dataset, threshold):
col_corr = set() # 相関列のすべての名前のセット
corr_matrix = dataset.corr()
for i in range(len(corr_matrix.columns)):
for j in range(i):
if abs(corr_matrix.iloc[i, j]) > threshold: # 絶対係数値
colname = corr_matrix.columns[i] # 列名を取得する
col_corr.add(colname)
return col_corr
corr_features = correlation(X_train, 0.8)
print('相関のある特徴量: ', len(set(corr_features)) )相関のある特徴量: 0
Wall time: 14.4 s
相関のある特徴量が存在しない。
フィルター法を適用した結果、削除できそうな特徴量がないことが分かりました。


