








*本記事は旧TechblogからCOLORSに統合した記事です。
械学習モデリングを行う際に、色々なモデル、色々な手法を試しないと良い結果を得ることができません。特にKaggleのコンペにおいては、モデルの予測スコアの差がほんの少しだけでも順位が全然違いますので時間を割いて試行錯誤する必要があります。
機械学習のモデリングの流れとして、「データ分析・データを理解」⇒ 「データに対する前処理」⇒「モデル構築」⇒「モデルで予測」のステップがあります。前回の記事はKaggleのNotebooks / Kernel機能で 「データ分析・データを理解」 を簡単に紹介しました。
前編:シンプルで高速特徴量の選択法
今回の記事では残りのステップをどのようにKaggleで効果的に行うかについて紹介したいと思います。
目次
1.効率的に前処理結果の利用法
2.高機能の無料GPUでモデル構築法
・GPU使用の設定
・前処理結果の読み込み
・GPUによるモデリング
・予測結果の作成
1.効率的に前処理結果の利用法
モデル構築にあたって、モデルが違っても同じ前処理結果を使うことが多いです。そのため、前処理結果を簡単に再利用することができたらかなりの時間が節約することができます。
◆ポイント
・ 前処理の最初から最後までを一つのNotebookで完結しましょう。
・モデル構築は別のNotebook を作って、「前処理」 Notebook の処理結果を参照に 。
# 必要なライブラリをインポート
import numpy as np
import pandas as pd
import gc
from sklearn.model_selection import train_test_split
# インプットデータファイルは "../input/" フォルダにあります。
import os
print(os.listdir("../input"))['sample_submission.csv', 'santander-customer-transaction-prediction.zip', 'target.feather',
'test.csv', 'test_extra_features.feather', 'test_ids_extra_features.feather',
'train.csv', 'train_extra_features.feather', 'train_ids_features.feather']
%%time
# データをロード
df_train = pd.read_csv("../input/train.csv")
df_test = pd.read_csv("../input/test.csv")Wall time: 13.5 s
X_train = df_train.drop(labels=['ID_code', 'target'], axis=1)
y_train = df_train['target']
X_test = df_test.drop(labels=['ID_code'], axis=1)
# 前処理の前に学習データとテストデータを結合
X_merge = pd.concat([X_train, X_test])
print("X_merge : ", X_merge.shape)
# メモリを解法
del X_train
del X_test
gc.collect()X_merge : (400000, 200)
0
◆ポイント
メモリ開放のために、使い終わったデータセットをこまめに削除しましょう。
def add_frequency_of_value(df):
'''
各特徴量内の値の頻度を新しい特徴量として追加する( 'ID_code'、 'target'を除く).
新しい項目の項目名は: 'var_X_count'になります。
'''
for var in df.columns:
df[var+'_count'] = df.groupby(var)[var].transform('count')
return df◆ポイント
学習データとテストデータは基本的に同じデータセットから分割されます。学習データとテストを別々に値の頻度を取得すると結果が大きく異なるかもしれません。よって、学習データを基いて構築したモデルはテストデータをよく予測することができません。
%%time
# 新しい特徴量の追加を行う
X_merge = add_frequency_of_value(X_merge)
print("X_merge's shape after: ", X_merge.shape)X_merge's shape after: (400000, 400)
Wall time: 43.8 s
X_train_freq = X_merge.iloc[0:200000]
X_test_freq = X_merge.iloc[200000:]
# メモリを解法
del X_merge
gc.collect()203
各説明変数が独立であるため、シャッフルデータを追加すること(データ拡張)で汎化性能が改善されると期待されます。
学習データに「目的変数=”0″」のデータが圧倒的に多いため、データを拡張する際に「目的変数=”1″」のデータを優先的に行います。
def shuffle_col_vals(x1):
#「特徴量内の値の頻度」と「その値」をセットにしてシャッフルする
rand_x_half = np.array([np.random.choice(x1.shape[0], size=x1.shape[0], replace=False) for i in range(x1.shape //2)]).T
rand_x = np.hstack([rand_x_half, rand_x_half])
grid = np.indices(x1.shape)
rand_y = grid
return x1[(rand_x, rand_y)]
def augment(x,y,t=2):
xs,xn = [],[]
for i in range(t):
mask = y==1
x1 = x[mask].copy()
x1 = shuffle_col_vals(x1)
xs.append(x1)
for i in range(t//2):
mask = y==0
x1 = x[mask].copy()
x1 = shuffle_col_vals(x1)
xn.append(x1)
xs = np.vstack(xs); xn = np.vstack(xn)
ys = np.ones(xs.shape[0]);yn = np.zeros(xn.shape[0])
x = np.vstack([x,xs,xn]); y = np.concatenate([y,ys,yn])
return x,y
//2)]).T
rand_x = np.hstack([rand_x_half, rand_x_half])
grid = np.indices(x1.shape)
rand_y = grid
return x1[(rand_x, rand_y)]
def augment(x,y,t=2):
xs,xn = [],[]
for i in range(t):
mask = y==1
x1 = x[mask].copy()
x1 = shuffle_col_vals(x1)
xs.append(x1)
for i in range(t//2):
mask = y==0
x1 = x[mask].copy()
x1 = shuffle_col_vals(x1)
xn.append(x1)
xs = np.vstack(xs); xn = np.vstack(xn)
ys = np.ones(xs.shape[0]);yn = np.zeros(xn.shape[0])
x = np.vstack([x,xs,xn]); y = np.concatenate([y,ys,yn])
return x,y元々の学習データを分割して、75%は新しい学習データ、25%は検証用データにします。
X_train,X_valid,y_train,y_valid = train_test_split(X_train_freq, y_train, test_size=0.25, random_state=42, stratify=y_train)
print(">> X_train shape: ", X_train.shape)
print(">> y_train shape: ", y_train.shape)
print(">> X_valid shape: ", X_valid.shape)
print(">> y_valid shape: ", y_valid.shape)>> X_train shape: (150000, 400)
>> y_train shape: (150000,)
>> X_valid shape: (50000, 400)
>> y_valid shape: (50000,)
学習データの拡張を行います。
%%time
X_train_aug, y_train_aug = augment(X_train.values, y_train.values, t=10)
print(">> X_train Augmented: ", X_train_aug.shape)
print(">> y_train Augmented: ", y_train_aug.shape)>> X_train Augmented: (975370, 400)
>> y_train Augmented: (975370,)
Wall time: 18.2 s
前処理結果の作成・確認を行います。
%%time
X_train_preprocessed = pd.DataFrame(data=X_train_aug, columns=X_train.columns)
y_train_preprocessed = pd.DataFrame(data=y_train_aug, columns=["target"])Wall time: 6.98 ms
# 前処理結果を確認
print(">> X_train shape: ", X_train_preprocessed.shape)
print(">> y_train shape: ", y_train_preprocessed.shape)
print(">> X_valid shape: ", X_valid.shape)
print(">> y_valid shape: ", y_valid.shape)
print(">> X_test shape: ", X_test_freq.shape)>> X_train shape: (975370, 400)
>> y_train shape: (975370, 1)
>> X_valid shape: (50000, 400)
>> y_valid shape: (50000,)
>> X_test shape: (200000, 400)
前処理結果をファイルに保存します。
%%time
X_train_preprocessed.to_csv("X_train.csv", index=False)
y_train_preprocessed.to_csv("y_train.csv", index=False)
X_valid.to_csv("X_valid.csv", index=False)
y_valid.to_csv("y_valid.csv", index=False)
X_test_freq.to_csv("X_test.csv", index=False)Wall time: 5min 58s
◆ポイント
前処理結果はファイルに保存することができました。この結果を他の Notebook からも参照できるために、コミットが必要です。Notebook 画面の右上の「Commit」ボタンをクリックして、コミットしてください。
この後のモデリングの処理はこの結果を使います。モデリングする時、前処理 Notebook の結果をインポートデータとして使いますので、もう一度前処理を行うことが必要ないです。 色々なモデルを試すことができますし、無駄な時間を省く可能になります。
2.高機能の無料GPUでモデル構築法
GPU使用の設定
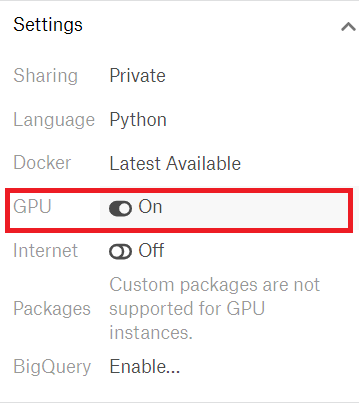
新しいNotebookを開いて、モデルの構築を行います。Notebookl画面の右側の「Settings」タブをクリックして、「GPU」の設定ところに「On」にします。
前処理結果の読み込み
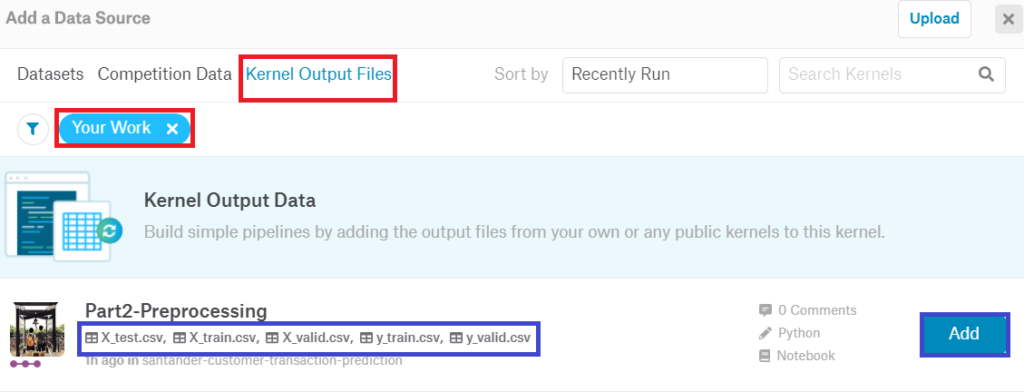
前処理Notebook からのアウトプット結果を読み込むことができます。
・ Notebook 画面の右上の「Add Data」ボタンをクリックします。
・「Add a Data Source」の画面にて、「 Kernel Output Files」>> 「Your Work」を選択すると、自分でコミットした Notebook とアウトプットファイルが表示されます。
・ 最後に、「Add」ボタンをクリックしたら、データが Notebook にロードされます。
それでは、ロードされた前処理結果を使ってモデリングを行って行きます。
import numpy as np
import pandas as pd
from sklearn.metrics import roc_auc_score
import catboost as ctb
import os
print(os.listdir("../input"))['part2', 'santander-customer-transaction-prediction']
# 追加したデータセットのリストを表示
print(os.listdir("../input/part2/"))['X_train.csv', 'custom.css', '__results__.html', 'y_valid.csv',
'X_test.csv', 'y_train.csv', '__output__.json', '__notebook__.ipynb', 'X_valid.csv']
前処理結果をロードします。
%%time
X_train = pd.read_csv("../input/part2/X_train.csv")
X_valid = pd.read_csv("../input/part2/X_valid.csv")
y_train = pd.read_csv("../input/part2/y_train.csv")
y_valid = pd.read_csv("../input/part2/y_valid.csv", names=['target'])
X_test = pd.read_csv("../input/part2/X_test.csv")CPU times: user 1min 26s, sys: 7.24 s, total: 1min 34s
Wall time: 1min 34s
# 確認
print(">> X_train shape: ", X_train.shape)
print(">> y_train shape: ", y_train.shape)
print(">> X_valid shape: ", X_valid.shape)
print(">> y_valid shape: ", y_valid.shape)
print(">> X_test shape: ", X_test.shape)>> X_train shape: (975370, 400)
>> y_train shape: (975370, 1)
>> X_valid shape: (50000, 400)
>> y_valid shape: (50000, 1)
>> X_test shape: (200000, 400)
GPUによるモデリング
Kaggleでよく利用されているGBDT(Gradient Boosting Decision Tree)系の機械学習モデルを実装していきます。
GBDTの代表としてXGBoost, LightGBM, CatBoostの機械学習モデルがあります。 今回はCatBoostモデルを構築して行きます。
・CatBoostモデルでGPUを使用する場合は、次のようにハイパーパラメータの設定が必要です:
’task_type’: ‘GPU’
・XGBoostモデルでGPUを使用する場合は、
’tree_method’: ‘gpu_hist’または
’tree_method’:’ gpu_exact ‘のハイパーパラメーターを設定してください。
・LighGBMモデルもGPUで学習することができますが、GPU LGBMの再コンパイルが必要のためすこし手間がかかります。
興味がある方はこのNotebook(by Vinh Nguyen)を参考して設定してみてください。⇒ GPU acceleration for LightGBM
LGBMモデルでGPUを使用する場合は、次の3つのハイパーパラメータの設定が必要です。
’device’: ‘gpu’,
’gpu_platform_id’: 0,
’gpu_device_id’: 0
# CatBoostモデルの設定は下記Notebookを参考しました。
# https://www.kaggle.com/zxspectrum/catboost-gpu
cat_params = {
'objective' : "Logloss"
,'eval_metric' : 'AUC'
,'task_type' : "GPU"
,'learning_rate' : 0.01
,'iterations': 70000
,'l2_leaf_reg': 50
,'random_seed': 42
,'od_type': 'Iter'
,'depth': 5
,'border_count': 64
,'colsample_bylevel' : 1.0
,'use_best_model': True
}%%time
clf = ctb.CatBoostClassifier(**cat_params)
clf.fit(X=X_train, y=y_train, eval_set=[(X_valid, y_valid)], verbose=5000, early_stopping_rounds = 3000)0: learn: 0.6284525 test: 0.6225534 best: 0.6225534 (0) total: 26ms remaining: 30m 19s
5000: learn: 0.9134591 test: 0.9046326 best: 0.9046326 (5000) total: 2m 9s remaining: 27m 58s
10000: learn: 0.9252063 test: 0.9148445 best: 0.9148445 (10000) total: 4m 22s remaining: 26m 13s
15000: learn: 0.9303286 test: 0.9178312 best: 0.9178312 (15000) total: 6m 33s remaining: 24m 3s
20000: learn: 0.9336329 test: 0.9189889 best: 0.9189889 (20000) total: 8m 44s remaining: 21m 51s
25000: learn: 0.9361914 test: 0.9195257 best: 0.9195274 (24975) total: 10m 55s remaining: 19m 40s
30000: learn: 0.9383949 test: 0.9197894 best: 0.9197907 (29997) total: 13m 4s remaining: 17m 25s
35000: learn: 0.9403480 test: 0.9199408 best: 0.9199420 (34997) total: 15m 11s remaining: 15m 11s
40000: learn: 0.9421456 test: 0.9200036 best: 0.9200174 (37788) total: 17m 20s remaining: 12m 59s
45000: learn: 0.9438407 test: 0.9200606 best: 0.9200655 (44839) total: 19m 26s remaining: 10m 48s
50000: learn: 0.9454644 test: 0.9200872 best: 0.9200909 (49960) total: 21m 36s remaining: 8m 38s
bestTest = 0.9200969934
bestIteration = 51977
Shrink model to first 51978 iterations.
CPU times: user 17min 26s, sys: 27min 22s, total: 44min 48s
Wall time: 25min 20s
約100万行 x 400カラムの学習時間は25分20秒でした。CPUの場合ですと、約40倍ぐらいの時間がかかりそうです。
# 評価関数
y_valid_pred = clf.predict_proba(X_valid)[:,1]
print(">> AUC Score: ", roc_auc_score(y_valid, y_valid_pred))>> AUC Score: 0.9200968311903643
予測結果の作成
# テストデータを予測
y_test_pred = clf.predict_proba(X_test)[:,1]# 提出用予測結果を作成
submission = pd.read_csv("../input/santander-customer-transaction-prediction/sample_submission.csv")
submission['target'] = y_test_pred
submission.to_csv('submission_cb.csv', index=False)◆ポイント
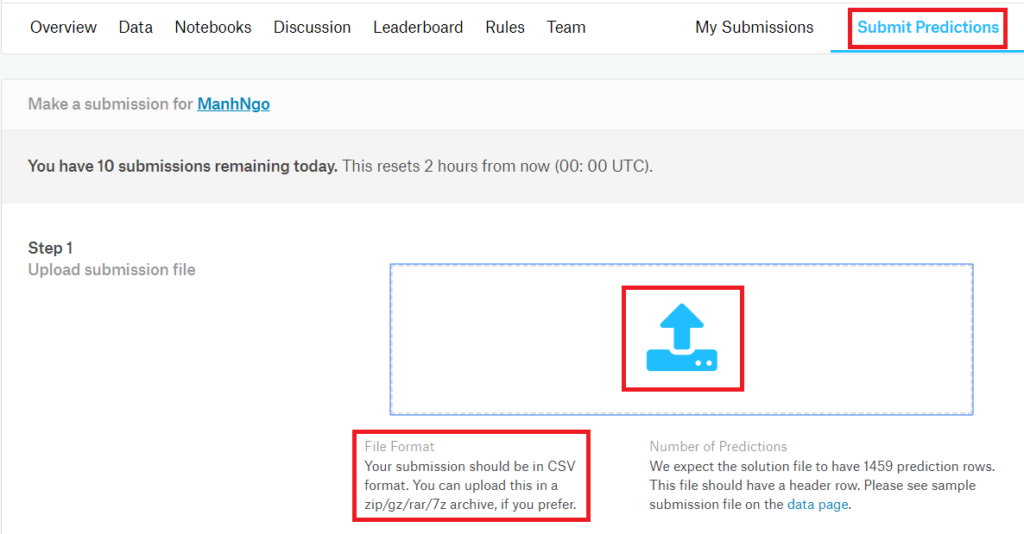
「Commit」ボタンをクリックすると予測結果を提出することが可能ですが、Notebook全体の処理時間によってコミット処理の時間がかかる場合があります。
ここまで処理したらすぐ結果を見たい、Public Scoreを見たいと思っている方が多いかと思います。コミット処理を待たずに、予測結果を提出する方法を紹介します:予測結果をファイルとしてローカルにダウンロードする方法です。
・Markdownセルに下記のように書いてください。そのセルを実行するとクリック可能の「Download File」ができます。
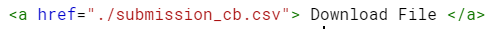

「Download File」をクリックして、予測結果をローカルにダウンロードできます。 ダウンロードしたファイルを使って提出できばと思います。
本記事はこれで以上になります。ご参考になれば幸いです。



