








AMBLで画像系AIアプリの開発を行っている見原です。好きな色は緑色です。
最新の物体検出モデル「YOLOv8」を使ってみましたので、使い方の共有と、実際に使ってみて私が躓いた点を共有したいと思います。
はじめに
今回のゴールはオリジナルデータセットを使い、モデルの学習を行えるようにすることです。
使用したリポジトリなどは以下の通りです。
- github: https://github.com/ultralytics/ultralytics
- Docs: https://docs.ultralytics.com/
- ファーストリリース: 2023/01
YOLOv8とは?
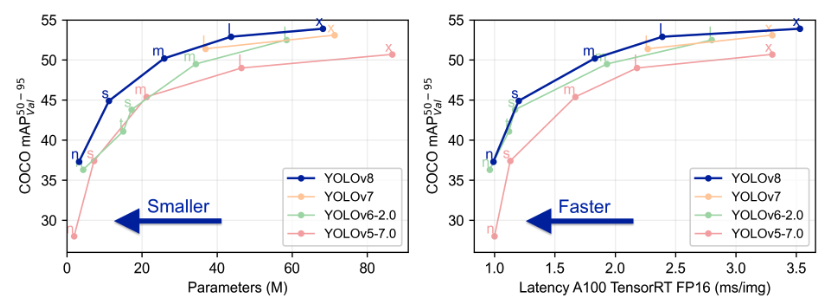
YOLOv5を開発したUltralyticsが開発したモデルです。今までのバージョンのYOLOよりも精度が高く、速いです(図参照)。物体検出だけでなく、画像分類やセグメンテーションも行うことができます。論文はまだ出ていないので詳しいアップデート内容は不明です。
使ってみよう
今回は、Google Colabを使ってYOLOv8の学習などを行いました。使用したノートブックは以下の通りです。
https://github.com/aifield/CV_News/blob/main/materials/2023/202302/yolov8.ipynb
まず、以下のコマンドでライブラリをインストールしてください。
| !pip3 install ultralytics |
3-1 物体検出
■データセットの準備
今回は以下のデータセットを使用しました。画像とラベルはOpen image datasetからダウンロードしました。
| class | train | valid | test |
| 1 (person) | 1000枚 | 333枚 | 500枚 |
以下のようなyamlファイルを作成します。学習を実行したときにFileNotFoundErrorが出る場合は、絶対パスを記載してください。
例 data.yaml
| names: [‘person’]nc: 1 test: /content/drive/MyDrive/yolo_practice/yolov8/datasets/person/test/imagestrain: /content/drive/MyDrive/yolo_practice/yolov8/datasets/person/train/imagesval: /content/drive/MyDrive/yolo_practice/yolov8/datasets/person/validation/images |
■学習
以下を実行して学習します。オプションを設定することができます。
| !yolo detect train data=data.yaml model=yolov8n.pt epochs=100 imgsz=416 device=0 batch=96 name=person |
デフォルト値は以下のファイルに書かれています。
https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/cfg/default.yaml
オプション
- data: データセットの情報が書かれているyamlファイルのパス
- model: モデルのパス (yolov5ではweightsとなっている)
- epochs: エポック数
- batch: バッチサイズ
- imgsz: 入力する画像サイズ
- optimizer: 最適化関数 [‘SGD’, ‘Adam’, ‘AdamW’, ‘RMSProp’]の中から選択できる
- close_mosaic: mosaicオーグメンテーションを行わない最後のエポック数(10とした場合最後から10エポックはmosaicオーグメンテーションを行わない)
■テスト
以下を実行してテストします。オプションを設定することができます。
splitオプションでテストに使用するデータセットを指定できます。デフォルトはvalidationデータとなっているので、testデータに対して精度評価を行いたい場合は、split=testとしてください。
| !yolo detect val model=”runs/detect/person4/weights/best.pt” data=data.yaml split=test conf=0.25 iou=0.45 |
オプション
- model: モデルのパス
- data: データセットの情報が書かれたyamlファイル
- split: 評価に使用するデータセット(デフォルトはvalとなっているので注意)
- conf: 信頼度の閾値(デフォルトは0.001)
- iou: NMSのiouの閾値(デフォルトは0.7)
■推論
以下を実行して推論します。オプションを設定することができます。
| !yolo detect predict model=”runs/detect/person4/weights/best.pt” source=”datasets/images” conf=0.25 iou=0.45 imgsz=416 |
オプション
- model: モデルのパス
- source: 画像や動画が入っているフォルダ
- conf: 信頼度の閾値(デフォルトは0.25)
- iou: NMSのiouの閾値(デフォルトは0.7)
- imgsz: 入力画像サイズ
- save_txt: 推論結果をテキストファイルで出力
- sace_conf: 推論結果をテキストファイルで出力するときに信頼度も記載する
- save_crop: bboxの箇所をcropして保存する(save_crop=Trueと書くとエラーが出る。save_cropのみ記載する)
- hide_labels: 推論結果を画像に表示するときにクラスラベルを表示しない
- hide_conf: 推論結果を画像に表示するときに信頼度を表示しない
- vid_stride: 動画に推論をかけるときのフレーム間隔
以下のような推論結果が得られました。画像から人を検出できました。
hide_labels=True hide_conf=Trueを設定すると、右図のようにバウンディングボックスのテキストを非表示にすることができます。

推論してバウンディングボックスがついた部分を切り出すことができます。デフォルトの設定だと切り出すときに少しパディングされます。パディングを無くしたい場合は、plotting.pyのsave_one_boxのパディングの値を0に変更してから実行する必要があります。
!yolo detect predict model=”runs/detect/person4/weights/best.pt” source=”datasets/images” conf=0.25 iou=0.45 imgsz=416 save=True save_crop |
3-2 画像分類
■データセット準備
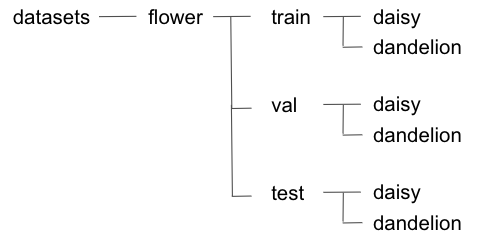
今回は、roboflowのflowerデータセットを使用しました。daisyとdandelionの2種類の花が含まれています。

以下のようなフォルダ構成でデータを格納します。
■学習
以下を実行して学習します。オプションは物体検出とほぼ同じです。
dataにtrain, valid, testの親ディレクトリを設定します(FileNotFoundErrorが出る場合は絶対パスを記載してください)。
| dataset_path = “/content/drive/MyDrive/yolo_practice/yolov8/datasets/flowers”!yolo classify train data={dataset_path} model=yolov8s-cls.pt epochs=100 imgsz=416 batch=96 device=0 name=flower |
■テスト
以下を実行してテストします。testデータに対して精度評価を行います。
| !yolo classify val model=”runs/classify/flower2/weights/best.pt” data={dataset_path} imgsz=416 split=test |
■推論
以下を実行して推論します。オプションは物体検出とほぼ同じです。
| !yolo classify predict model=”runs/classify/flower2/weights/best.pt” source=”datasets/flowers_sample” imgsz=416 |
以下のような推論結果が得られました。画像の左上に各クラスの信頼度が表示されています。

3-3 セグメンテーション
■データセット準備
今回はcoco128-segデータセット(https://ultralytics.com/assets/coco128-seg.zip)を使用しました。
物体検出と同じように、1つの画像につき1つのテキストファイルが対応するようになっています。ラベルの形式は以下の通りです。

以下のようなyamlファイルを作成します。学習を実行したときにFileNotFoundErrorが出る場合は、絶対パスを記載してください。
今回はtrain, val, testに同じデータセットを設定しています。
例 coco128-seg.yaml
| train: /content/drive/MyDrive/yolo_practice/yolov8/datasets/coco_segmentation/images/train2017 val: /content/drive/MyDrive/yolo_practice/yolov8/datasets/coco_segmentation/images/train2017 test: /content/drive/MyDrive/yolo_practice/yolov8/datasets/coco_segmentation/images/train2017 # Classesnames: 0: person 1: bicycle 2: car 3: motorcycle 4: airplane 5: bus : : : |
■学習
以下を実行して学習します。オプションは物体検出とほぼ同じです。
| !yolo segment train data=coco128-seg.yaml model=yolov8s-seg.pt epochs=100 imgsz=416 batch=16 device=0 name=coco128 |
■テスト
以下を実行してテストします。オプションは物体検出とほぼ同じです。
| !yolo segment val model=yolov8s-seg.pt data=coco128-seg.yaml split=test conf=0.25 iou=0.45 |
■推論
以下を実行して学習します。オプションは物体検出とほぼ同じです。
| !yolo segment predict model=yolov8s-seg.pt source=”datasets/images” conf=0.25 iou=0.45 |
以下のような推論結果が得られました。boxes=Falseとすると右図のようにbboxが描画されません。
save_txt=Trueとすると、YOLO形式でラベルが保存されます。

おわりに
YOLOv8は、YOLOv5, YOLOv7を使ったことがあれば、ほぼ同じように使うことができます。Docsを読んだだけでは使い方がよくわからない部分もありましたので、この記事が参考になりましたら幸いです!最近はYOLOv8を使って姿勢推定もできるようになったようなので試してみたいです!
参考資料
あなたも一緒にAMBLで働いてみませんか?
AMBLは事業拡大に伴い、一緒に働く仲間を通年で募集しています。
データサイエンティスト、Webアプリケーションエンジニア、AWSエンジニア、ITコンサルタント、サービス運用エンジニアなどさまざまな職種とポジションで、自分の色を出してくださる方をお待ちしています。ご興味のある方は、採用サイトもご覧ください。
●AMBL採用ページ
-メンバーインタビュー (1日の仕事の流れ/やりがい/仕事内容)
-プロジェクトストーリー (プロジェクトでの実績/苦労エピソード)
●募集ページ
プリセールス/ エンジニア/ クリエイター/ データサイエンティスト /営業・コンサルタント /コーポレート /サービス企画 /教育担当




