*本記事は旧TechblogからCOLORSに統合した記事です。
こんにちは。株式会社エイアイ・フィールドのK.Tと申します。
現在、機械学習やディープラーニングを用いたレコメンドエンジンの開発に携わっています。今回、業務においてBERTを利用した類似文書の検索について学ぶ機会があり、実際に試してみたので記事にしたいと思います。
目次
- BERTとは
- BERTを用いた類似文書の検索
- 使用するモデルについて
- 実行環境
- ソースコード
- 下準備
- データセットの読み込み
- 文書の特徴ベクトル化
- 類似文書の検索
- 検索結果の可視化
- まとめ
BERTとは
BERTとは2018年にGoogleが発表した自然言語処理の深層学習モデルです。
BERTはBidirectional Encoder Representations from Transformersの略で、自然言語処理における様々なタスク(質疑応答、翻訳、文書要約etc.)において当時のSoTA(最新記録)を記録しました。現在もBERTの構造を改良した様々なモデルが発表され続けており、深層学習を用いた自然言語処理に大きな影響を与えています。
ここではモデルの詳細には触れませんが、こちらのページの解説が詳しいので興味のある方は見てみてください。
BERTを用いた類似文書の検索
今回はBERTの日本語学習済みモデルを用いて、類似文書の検索を行ってみます。
データセットにはLivedoor Newsコーパスを用います。Livedoor Newsコーパスは9つのグループに分けられたニュース記事のデータセットです。ある記事と類似した内容の記事をBERTを用いて検索してみたいと思います。データセットはこちらのページで公開されています。
使用するモデルについて
Huggingface が公開しているライブラリtransformersを利用してBERTの日本語学習済みモデルを使用します。
transformersを使用することで tensorflow または pytorch のBERTの日本語学習済みモデルを簡単に呼び出して使用することができます。
今回はpytorchを使って BERT の日本語学習済みモデルを動かしたいと思います。
実行環境
Google Colaboratoryを使用しました。
ソースコード
下準備
データセットのダウンロードと必要なライブラリのインストールを行います。
mecab-python3 はそのままインストールするとBERTのトークナイズ時にエラーになってしまったので、バージョン指定してインストールしています。
%%bash # データセットのダウンロード wget https://www.rondhuit.com/download/ldcc-20140209.tar.gz tar xvzf ldcc-20140209.tar.gz # ライブラリのインストール apt install aptitude swig aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y pip install mecab-python3==0.996.5 #pip install mecab-python3 pip install unidic-lite nlplot japanize-matplotlib transformers fugashi ipadic
データセットの読み込み
ライブラリのインポートとデータセットの読み込みを行います。
import os
import re
import numpy as np
import pandas as pd
from tqdm.notebook import tqdm
tqdm.pandas()
import nlplot
import warnings
warnings.simplefilter('ignore')
import torch
import transformers
from transformers import BertJapaneseTokenizer
import logging
logging.getLogger("transformers.tokenization_utils_base").setLevel(logging.ERROR) # tokenize時の警告を抑制
def load_dataset():
"""データセットの読み込み"""
paths = []
for dirpath, dirnames, filenames in os.walk('./text'):
for file in filenames:
if re.match(r'.+[0-9].txt', file):
#print("{0}".format(file))
paths.append(os.path.join(dirpath, file))
data = {
'path': [],
'URL': [],
'date': [],
'title': [],
'text': [],
}
for path in paths:
with open(path, 'r') as f:
url = f.readline().strip('¥n')
date = f.readline().strip('¥n')
title = f.readline().strip('¥n')
text = f.read()
data['path'].append(path)
data['URL'].append(url)
data['date'].append(date)
data['title'].append(title)
data['text'].append(text)
return pd.DataFrame(data)
df = load_dataset()
load_datasetを実行すると以下のようなデータセットのパス、記事のURL、日付、記事のタイトル、本文を格納した DataFrame を返します。

文書の特徴ベクトル化
BertExtractorクラスで日本語学習済みモデルのトークナイザーと学習済みモデルを読み込み、記事の本文を特徴ベクトル化します。
学習済みモデルの使用の流れとしては、使用するトークナイザーとモデルをfrom_pretrained 関数を使用して呼び出し、トークナイザーで文書の分かち書きを行いベクトル化したものをモデルに入力し、文書の特徴ベクトルを取り出すという形になります。呼び出している学習済みモデルは東北大学の乾研究室が作成したものになります。
class BertExtractor:
"""文書特徴抽出用クラス"""
def __init__(self):
self.device = 'cuda' if torch.cuda.is_available() else 'cpu' #GPUが使用可能ならGPUを使用
self.model_name = 'cl-tohoku/bert-base-japanese-whole-word-masking' #使用する学習済みモデル名
self.tokenizer = BertJapaneseTokenizer.from_pretrained(self.model_name) #使用するBERTトークナイザー
self.bert_model = transformers.BertModel.from_pretrained(self.model_name) #学習済みモデル呼び出し
self.bert_model = self.bert_model.to(self.device)
self.max_len = 128 #使用する入力文書の長さ。最大512まで
def extract(self, sentence):
"""文書特徴ベクトルを抽出する"""
# 文書のトークナイズ
inp = self.tokenizer.encode(sentence)
len_inp = len(inp)
# 入力トークン数の調整
if len_inp >= self.max_len:
inputs = inp[:self.max_len]
else:
inputs = inp + [0] * (self.max_len - len_inp)
# モデルへ文書を入力し特徴ベクトルを取り出す
inputs_tensor = torch.tensor([inputs], dtype=torch.long).to(self.device)
seq_out, _ = self.bert_model(inputs_tensor)
if torch.cuda.is_available():
return seq_out[0][0].cpu().detach().numpy() # 0番目は [CLS] token, 768 dim の文章特徴量
else:
return seq_out[0][0].detach().numpy()
extract 関数で各記事の特徴ベクトルを取り出し、text_feature カラムに格納します。
その後 cos_sim_matrix 関数で各記事の特徴ベクトル間のコサイン類似度行列を計算し、返却しています。
def cos_sim_matrix(matrix):
"""文書間のコサイン類似度を計算し、類似度行列を返す"""
d = matrix @ matrix.T
norm = (matrix * matrix).sum(axis=1, keepdims=True) ** .5
return d / norm / norm.T
bex = BertExtractor()
df['text_feature'] = df['text'].progress_apply(lambda x: bex.extract(x)) # 文書の特徴ベクトル化
sim = cos_sim_matrix(np.stack(df.text_feature)) # 類似度行列
類似文書の検索
ランダムに記事を一つ選び、その記事との類似度が高い順に記事を100件取り出す search 関数を作成し、検索結果を DataFrame 化してみます。
def search(n=100):
doc = df.sample(1)
doc_idx = doc.index[0]
sim_index = sim[doc_idx].argsort()[::-1]
rec_df = df.iloc[sim_index][:n]
rec_df['similarity'] = np.sort(sim[doc_idx])[::-1][:n]
return rec_df[['title', 'text', 'similarity']]
df2 = search()
search 関数を実行すると以下のような DataFrame が作成されます。1番上に表示されている記事がランダムに取り出した記事で、2番目以降に1番目の記事と類似した記事が類似度順に並んでいます。similarity カラムはその記事の特徴ベクトルと先頭記事の特徴ベクトルとの類似度を表しており、先頭文書の similarity は自分自身との類似度を表すため1になっています。

今回は女子サッカーに関する記事が選ばれ、それと類似度の高い記事が2番目以降に並んでいます。サッカーやオリンピックといったスポーツ関連の記事が多く並んでいそうです。
検索結果の可視化
検索結果の100件の記事の内容を bi-gramとwordcloudを使って可視化してみます。
可視化には nlplot をいうライブラリを使用します。自然言語処理の可視化を簡単に行うことができ便利です。
nlplot を使用するためには記事の本文をトークナイズする必要があるため、tokenize 関数を使用して本文をトークナイズします。
def tokenize(text,):
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
wakati_ids = tokenizer.encode(text, return_tensors='pt')
tokens = tokenizer.convert_ids_to_tokens(wakati_ids[0].tolist())
return tokens[1:-1] #[CLS], [SEP]トークンを除く
df2['tokenized_text'] = df2['text'].progress_apply(tokenize)
トークナイズ後、nlplot を使用し bi-gram の出現頻度を棒グラフで表示してみます。ノイズ単語除去のため stopwords で出現頻度の多い単語の上位20個を表示結果から除くように指定しています。
npt = nlplot.NLPlot(df2, target_col='tokenized_text')
# top_nで頻出上位単語, min_freqで頻出下位単語を指定できる
stopwords = npt.get_stopword(top_n=20, min_freq=0)
# bi-gram表示
npt.bar_ngram(
title='bi-gram',
xaxis_label='word_count',
yaxis_label='word',
ngram=2,
top_n=50,
stopwords=stopwords,
)
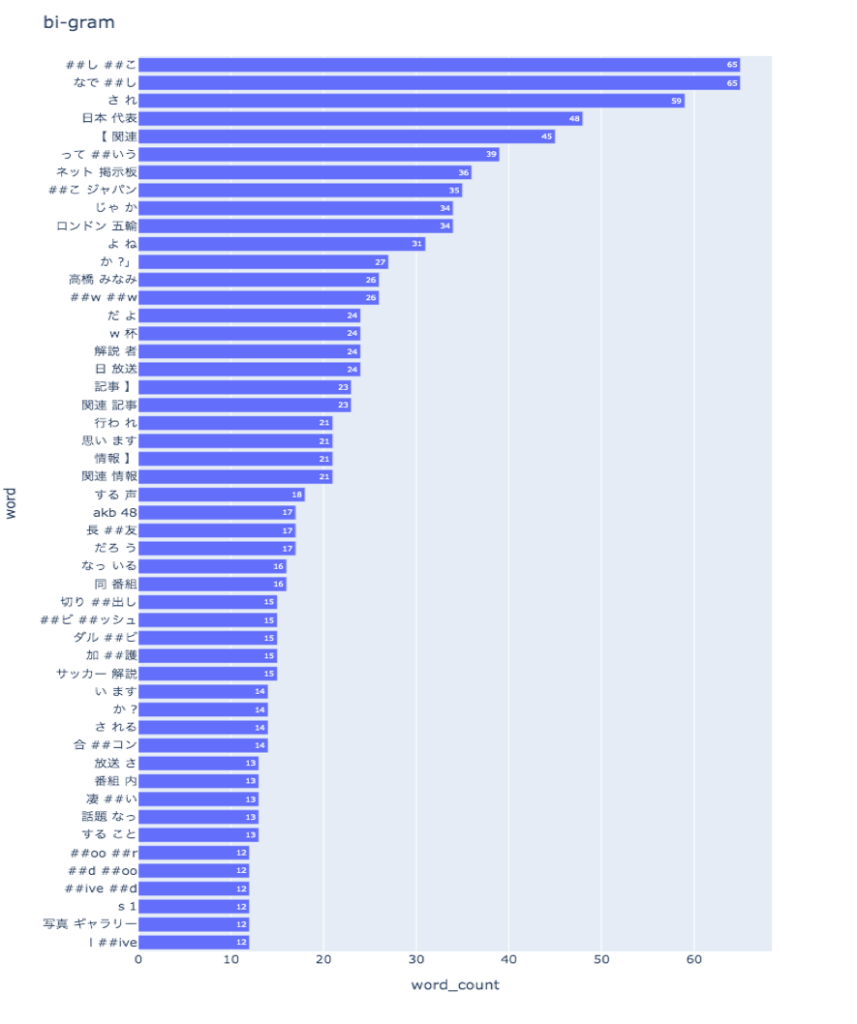
上位に「なでしこ」という単語の一部が来ていたりと、女子サッカーに関連していそうな言葉が上位に来ており、類似したニュース記事が検索できていそうです。続いてwordcloudも表示してみます。
npt.wordcloud(
max_words=100,
max_font_size=100,
colormap='tab20_r',
stopwords=stopwords,
)
結果は以下のようになりました。選択した記事と類似した記事を取り出すことができていることがわかりますね。

まとめ
BERT を使用した文書の検索を行い、類似文書の特徴を抽出できることがわかりました。文書の検索やレコメンドへの応用ができそうです。
BERT には他にも分類や質疑応答などさまざまな応用方法がありそうなので、引き続き勉強していきたいと思います。