








*本記事は旧TechblogからCOLORSに統合した記事です。
1.自己紹介
こんにちは。エイアイ・フィールドのA.Sです。
今回は、画像処理で顔文字をAIで正しく分類できるかやっていきます!!
前回は、自然言語処理で「かわいい、キモい、しょぼん、挨拶、驚き、焦り、笑、怒」の
8種類の顔文字を約66.7%の精度で分類することができました。
■前回の記事
https://colors.ambl.co.jp/classify-kaomoji-with-ai/
2.使用する顔文字
前回と同様にSimejiの顔文字辞典から顔文字を一部使用させて頂きました。
https://simeji.me/blog/%E9%A1%94%E6%96%87%E5%AD%97-%E4%B8%80%E8%A6%A7/kaomoji/id=10021
使用する顔文字は全部で690個です。
カテゴリはかわいい、キモい、しょぼん、挨拶、驚き、焦り、笑、怒の8種類。
3.画像処理で実験!!
直感的には自然言語処理より画像処理のほうが相性がいいと思いますよね。果たしてどれくらいの精度がでるのか!
3.1 顔文字を画像化する
Excelのセルに保存されている顔文字をそのままVBAで画像に変換しました。
特殊な文字が多いのでそれが一番手っ取り早かったです(★‿★) サイズは64×64です。
3.2 画像の水増し
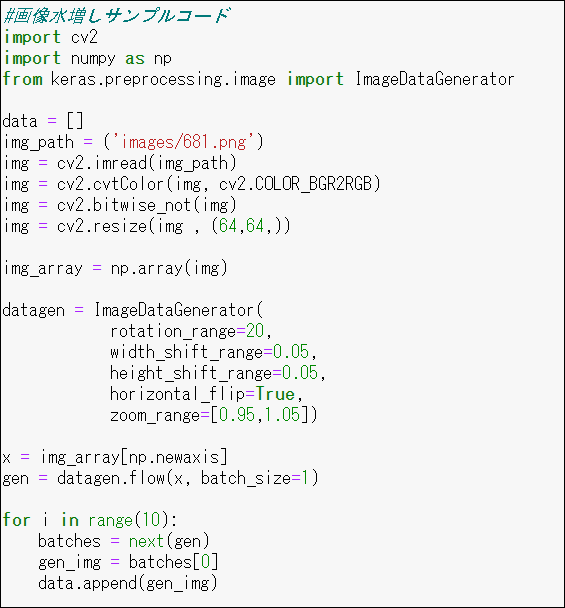
690枚ではデータが少なかったので、OpencvとkerasのImageDataGeneratorで
回転・拡大・縮小して10倍に増やしました。また精度の向上を狙って白黒を反転させました。
■データ一覧
データ水増し 629枚 → 6290枚
訓練データ 5589枚(水増しデータ9割)
検証データ 621枚(水増しデータ1割)
テストデータ 61枚

3.3 画像を正規化
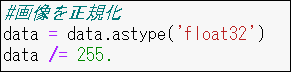
画像を255で割ることで0~1までの数値に変換します。こうすることで学習が早く進みます。
3.4 目的変数のカテゴリをOne hot vectorに変換
自然言語処理時と同様です。10倍に水増ししているので10倍作る必要があります。https://colors.ambl.co.jp/2020/05/27/classify-kaomoji-with-ai/
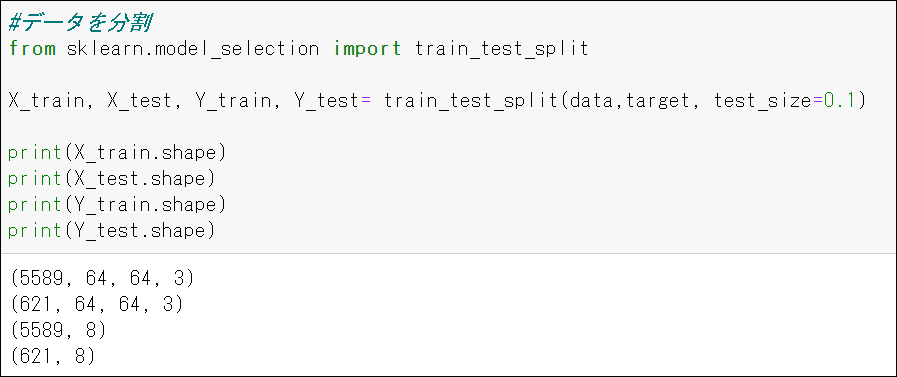
3.5 水増しデータを訓練データと検証データに分割(9:1)&テストデータ作成
説明変数が64×64×3の画像になっていることが確認できます。
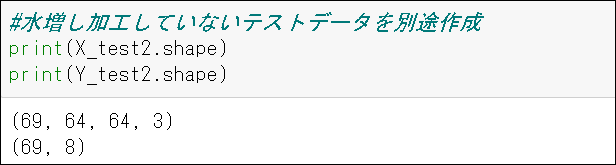
また、水増し加工していないテストデータを取得。
3.6 標準的なCNNのモデルで学習
3.6.1 モデルの全体像
このような構造です。フレームワークはkerasを使用しています。

3.6.2 CNNとは?
wikipediaではCNN(Convolutional Neural Networks )とは、全結合していない順伝播型ニューラルネットワークの一種。
特に2次元の畳込みニューラルネットワークは人間の視覚野のニューロンの結合と似たニューラルネットワークであり、
人間の認知とよく似た学習が行われることが期待されると記載されています。
今回のモデルはごく一般的なCNNを採用しています。畳み込み層(conv2d)とMax pooling2dを多層にしています。各層の間にbatch normalizationを挟み精度の向上を狙っています。最終層はGrobal Average poolingを使用してパラメータ数を節約しています。
3.6.3 モデルを学習
バッチサイズ 64で、訓練データを150周学習させました。(150epoc)
学習のcompileは下記のとおりです。

3.7 テストデータで精度確認
精度は約49.2%でした!!なんと自然言語処理より精度が低い結果に。。

4.まとめ
画像処理は49.2%という結果でした。自然言語処理は66.7%。意外でした。。
データが増えたらどういう結果になるのか?画像処理と自然言語処理を組み合わせた
AIのモデルだとどうなるか?興味のある方はぜひチャレンジしてみてください。




