








*本記事は旧TechblogからCOLORSに統合した記事です。
こんにちは、エンジニアソリューション事業部のA.Sです。
今回は、ラズベリーパイのカメラと前回インストールしたOpenCVを利用して、
リアルタイムでの顔認識を行います。
顔認識は、
LBPH(Local Binary Patterns Histogram)での顔分析モデルを作成し、
事前に顔認識学習済か否かで判別を行います。
下記構成となっています。
- ①写真撮影(顔の学習のためラズベリーパイのカメラで写真撮影)
- ②顔分析モデル作成(上記①で撮影した写真を学習)
- ③顔検知(顔分析モデルを利用し、学習した顔があるか検知)
※OpenCVは、下記でも紹介
①写真撮影(顔の学習のためラズベリーパイのカメラで写真撮影)
顔を学習するための素材として写真撮影を行います。
下記、GetFace.pyを実行すると撮影が始まります。
顔検知後に撮影となるため、認識されない場合は少し離れたり角度を変えたりしてください。
また実行時の引数は下記に記載していますが、
第一引数のユーザIDは数値でナンバリングしてください。(Aさんは1、Bさんは2のように)
※OpenCVの顔学習の関数(train())では、数値でしか判別(マッピング)できないため。
第二引数は、撮影枚数です。撮影枚数が多いほど学習量も増えます。
GetFace.py(第一引数:ユーザID【数値】、第二引数:撮影枚数)
import cv2 import os import sys #画像保存先 path = "/home/pi/blog3/ReadFace/self" #ユーザID(写真に名称付与) #また、LBPHFaceRecognizerから生成する際、数値によるナンバリングしか行えない模様。train()の第二引数は数値の配列のみのようだったため user_id = sys.argv#顔画像の取得(撮影)枚数 takeCnt = int(sys.argv
) print("ユーザID:"+ user_id +"の顔データを取得します。全" + str(takeCnt) +"枚撮影") print("出力先:" + path) print("--撮影中--") #公式サイトで入手したカスケードxmlファイルを指定。今回は、顔、正面のみ。 face_cascade = cv2.CascadeClassifier('/home/pi/temp_face/data/haarcascades/haarcascade_frontalface_default.xml') #カメラデバイス起動(ビデオモード) pcam = cv2.VideoCapture(0) #実撮影枚数 cnt = 0 #撮影状態維持のため while True: ret, img = pcam.read() #グレースケールでなくともよいがグレースケールが一般的のようなので、 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #解析する幅。小さくすれば正確だが時間がかかる。 faces = face_cascade.detectMultiScale(gray, 1.3, 5) #多少間を空けるために設定(短時間での連続撮影だと類似画像になるため) cv2.waitKey(100) for x,y,w,h in faces: #検出した領域の枠を描画、「(255,0,0),2」は()の左から青、緑、赤。右端は線の太さ。 cv2.rectangle(img, (x,y), (x+w,y+h), (255,0,0), 0) #画像保存。gray[y:y+h,x:x+w]は、顔認識の四角の範囲で切り出した部分。 cv2.imwrite("/home/pi/blog3/ReadFace/self/" + str(user_id) + '.' + str(cnt) + ".jpg", gray[y:y+h,x:x+w]) #カウント用 cnt += 1 print("顔データ収集中:" + str(cnt) +"/" + str(takeCnt) + " 枚目") #プレビュー用 cv2.imshow('image', img) #撮影予定枚数を満たしていたらbreak if cnt >= takeCnt: break #カメラデバイス終了 pcam.release() #プレビュー閉じる cv2.destroyAllWindows() print("顔データ収集完了")
撮影すると確認のためプレビューが起動します。
プレビューは撮影完了後に閉じます。
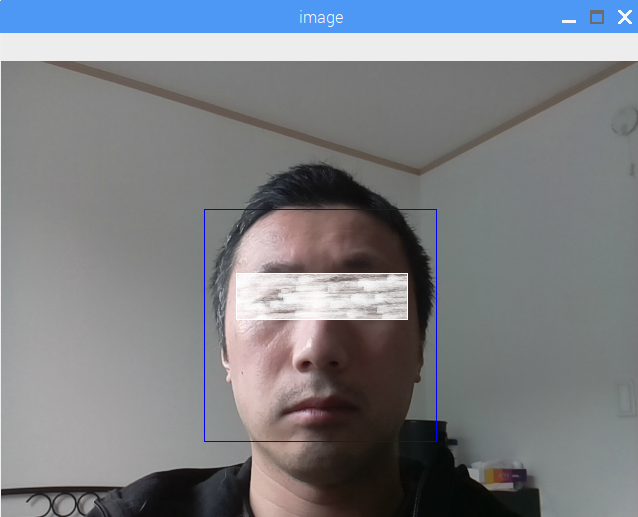
※目の白い部分は別途隠したもので処理とは関係ありません。
実行結果
>>> %Run GetFace.py 1 30 ユーザID:1の顔データを取得します。全30枚撮影 出力先:/home/pi/blog3/ReadFace/self --撮影中-- 顔データ収集中:1/30 枚目 顔データ収集中:2/30 枚目 顔データ収集中:3/30 枚目 ・・・ 顔データ収集中:30/30 枚目 顔データ収集完了
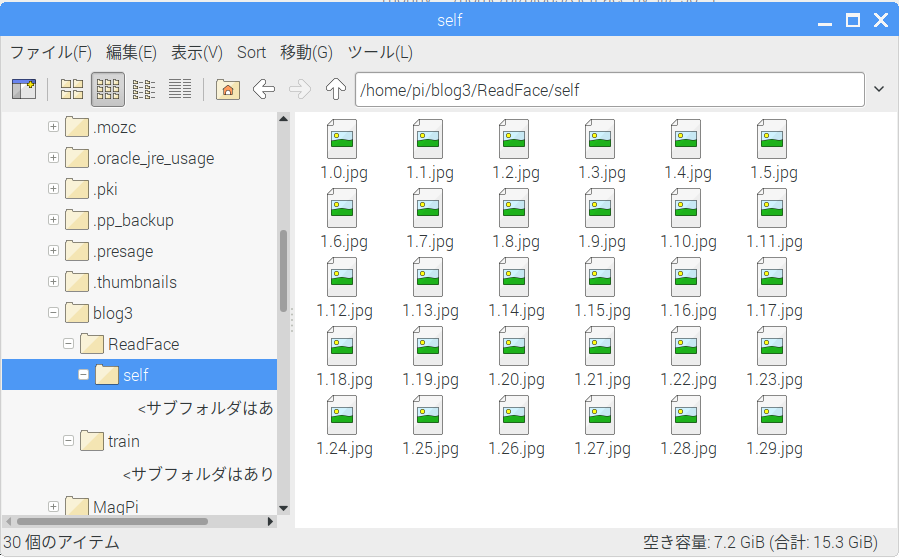
[ユーザID].[撮影枚数].jpg形式
②顔分析モデル作成(上記①で撮影した写真を学習)
撮影した写真を学習し、顔分析モデルを作成します。
OpenCVのLBPHFaceRecognizer_create()を利用し、
画像学習[train()]、学習結果のファイル出力[write()]を行います。
※出力されたファイルは顔分析モデルとして利用します。
また、LBPHFaceRecognizer_create()は、
[opencv-contrib-python]をインストールする必要があります。
[opencv-contrib-python]は、[opencv-python]と共存できないようで両方入っているとエラーになりました。
opencv-pythonアンインストール
sudo pip3 uninstall opencv-python
opencv-contrib-pythonインストール
sudo pip3 install opencv-contrib-python
LeaningFace.py
import cv2
import numpy as np
from PIL import Image
import os
# 画像データのパスを指定
path = '/home/pi/blog3/ReadFace/self'
#カスケードxmlファイルを指定。顔、正面。
detector = cv2.CascadeClassifier("/home/pi/temp_face/data/haarcascades/haarcascade_frontalface_default.xml")
#解析モデル出力
outPath = '/home/pi/blog3/train/train.yml'
# 画像データとラベル(id)を取得する関数
def mapImageLabel(path):
#顔画像データの取得
images = [os.path.join(path,f) for f in os.listdir(path)]
#画像データ
imgSamples=[]
#画像ID rain()の第二引数は数値の配列のみのようだったためLBPHFaceRecognizerから生成する際、数値によるナンバリングしか行えない模様
ids = []
# 各画像をループで
for image in images:
#取得元がグレースケール化していない場合は、Image.open(imagePath).convert('L')でグレースケール化する。
#GetFace.py経由だとグレーアウト済みのため割愛
#uint8は、8ビットの符号なし整数
img = np.array(Image.open(image),'uint8')
#GetFace.pyで撮影したファイル名は、XX.YY.jpg。(XXはIDの意味付けをさせており、この部分を取得)
id = int(os.path.split(image)[-1].split(".")[0])
#解析
faces = detector.detectMultiScale(img)
for x,y,w,h in faces:
#解析結果を格納
imgSamples.append(img[y:y+h,x:x+w])
ids.append(id)
return imgSamples,ids
#解析された画像とユーザーIDを取得
faces,ids = mapImageLabel(path)
#LBPH顔認識用インスタンス生成
recognizer = cv2.face.LBPHFaceRecognizer_create()
#顔認識用トレーニング(学習)開始
print("トレーニング開始")
recognizer.train(faces, np.array(ids))
#トレーニング(学習)結果をファイル出力
recognizer.write(outPath)
print("トレーニング終了 結果:" + outPath)
実行結果
%Run LeaningFace.py
トレーニング開始
トレーニング終了 結果:/home/pi/blog3/train/train.yml
③顔検知(顔分析モデルを利用し、学習した顔があるか検知)
上記②で作成した顔分析モデル(ymlファイル)を利用し、
カメラに学習した顔に似ている顔が映った場合に検知し、
ユーザ名と類似率を表示します。
※登録されていない顔が映った場合は、「who?」を表示します。
下記は、最低限の設定で試しています。
ここの実装でカメラや環境に合わせたチューニングをすれば認識率は高まるようです。
import cv2
import numpy as np
import os
#LeaningFace.pyでトレーニング(学習)した結果を読み込む
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('/home/pi/blog3/train/train.yml')
faceCascade = cv2.CascadeClassifier("/home/pi/temp_face/data/haarcascades/haarcascade_frontalface_default.xml")
font = cv2.FONT_HERSHEY_SIMPLEX
#IDを名前に変換するための配列(ユーザー増やす場合やIDが大きい場合は別の方法で取得するほうが良さそう)
#下記は、ID0~2の3ユーザーのみ
users = ['ID:0, Name', 'ID:1, A.S', 'ID:2, S.A']
print("--撮影開始--")
#カメラデバイス起動(ビデオモード)
pcam = cv2.VideoCapture(0)
#起動状態保持のため
while True:
ret, img = pcam.read()
#グレースケールでなくともよいがグレースケールが一般的のようなので、
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(gray, 1.3, 5)
for x,y,w,h in faces:
cv2.rectangle(img, (x,y), (x+w,y+h), (0,255,0), 0)
#信頼度0が完全一致
id, confidence = recognizer.predict(gray[y:y+h,x:x+w])
if (confidence == 100):
id = "Who?"
else:
#id-名前に変換
id = users[id]
#名前表示
cv2.putText(img, str(id), (x+5,y-5), font, 1, (255,255,255), 2)
#信頼度表示(%表示)
confidence = str(" {0}%".format(round(100 - confidence)))
cv2.putText(img, confidence, (x+5,y+h-5), font, 1, (255,255,0), 1)
print("人物の顔を確認:" + id + confidence)
#プレビュー表示
cv2.imshow('image', img)
#画像撮影頻度調整かつEscキー入力による処理終了受付用
k = cv2.waitKey(10)
if k == 27:
break
#カメラデバイス終了
pcam.release()
#プレビュー閉じる
cv2.destroyAllWindows()
print("--撮影終了--")
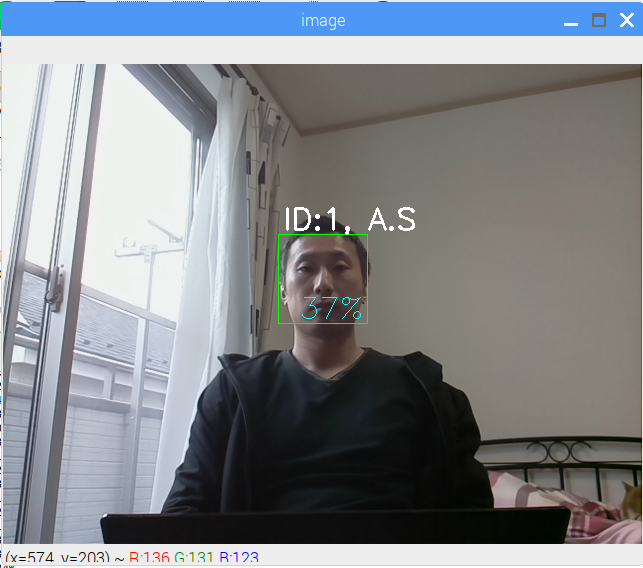
実行結果
%Run UseOrgRec.py
--撮影開始--
人物の顔を確認:ID:1, A.S 39%
人物の顔を確認:ID:1, A.S 40%
・・・
人物の顔を確認:ID:1, A.S 33%
--撮影終了--
以上で、顔認識処理の説明は終わりです。
今後はチューニングや学習素材を増やしていろいろ試したいと思います。
おまけ
久しぶりにラズベリーパイ触ったところ、
(パスワード変更した覚えがないが)パスワードが異なるようで、
sshやRDP接続できない事象が発生。
下記でデフォルトのパスワード(raspberry)に戻す。
sudo passwd pi
ちなみに下記は、ノートPCからラズベリーパイにRDP接続するためのモジュール
sudo apt install tightvncserver sudo apt install xrdp




