








*本記事は旧TechblogからCOLORSに統合した記事です。
◆はじめに
こんにちは。データマイニング推進部のミシェル(仮名)です。
機械学習はおろか統計の「と」の字も知らなかった、文系学部出身の私が
SIGNATEという人工知能コンペティションサービスで機械学習予測モデル作成に挑戦し
9位/2070人中(※2019/2/9時点)を達成したお話をします!
☆自己紹介
2018年度新卒入社。エム・フィールド1年生です。
入社後の4月~6月は、プログラミング研修にて基礎知識を身に着け、
7月からデータマイニング推進部に配属されました。
さらに、7月~10月は社内でSQL、Pythonの研修を行った後、
10月末から本格的に機械学習を学び始めました。
—-データマイニング推進部とは?—-
データ分析により、クライアント企業様への改善策のご提案を行ったり、
機械学習等による業務改善システムの作成を行っている部署になります。
☆SIGNATEへのチャレンジのきっかけ
これから機械学習を学ぶにあたってまずはどうすべきか、
OJTトレーナーを担当して頂いた同部署のY.Sawaiさんに相談しました。
※Y.SawaiさんはAI技術専門のスクールで機械学習を学び、
2018年10月にエム・フィールドに入社された方です。
そこで、いきなり業務に入るより、まずはSIGNATEにチャレンジしよう!
ということになり、レクチャーしていただきながら
私の機械学習への第一歩がスタートしたのです。。。
☆SIGNATE(しぐねいと)とは?
データ分析のコミュニティサイトです。
企業が問題解決のために提供したデータを、一般のエンジニアが用いて予測モデルを作成し、
作成したモデルの精度を競い合うコンペの開催など行われます。
◆機械学習による予測モデル作成とは?
☆そもそも、予測モデルって何…?
例えばある商品の売り上げが伸びたとき、そこには何らかの要素があります。
価格、デザイン、販売時期などなど…。
この要素の関係性をよく調べ計算式に表せば
「ではこの価格なら?このデザインでは?」
と条件を変えたときでも売り上げの予想が立てられそうですね。
この計算式が「予測モデル」にあたります。
そしてこの予測モデルは、
機械学習アルゴリズム(データを処理してくれる仕組み)が
大量のデータを学習して、計算式の塊(=予測モデル)を作ってくれます。
これが「機械学習による予測モデル作成」です。
この予測モデルに、新たなデータを当てはめることで様々な予測が可能になります。
☆予測モデル作成にはどんな作業が必要なの?
機械学習アルゴリズムが、良い予測モデルを作れるように
私たちが行うのは主に以下になります。
- 学習させるデータを綺麗にする・加工する
- どんなアルゴリズムを使用するか選ぶ
- アルゴリズムの設定の調整
◆SIGNATE課題内容
それでは、今回取り組んだ課題内容について説明していきます!
☆今回の課題は?
練習問題として無期限で参加することのできる、
「お弁当の需要予測」という課題に取り組みました。
☆何を予測するの?
ある会社のカフェフロアで販売されているお弁当の売上数を予測するモデルを作成します。
曜日、気温、メニュー等の複数の要素から予測モデルを作成し、
「この条件ではどのくらいお弁当が売れるのか?」を予測することで、
売上向上や売れ残りの削減に繋げます。
☆どんなデータを使うの?
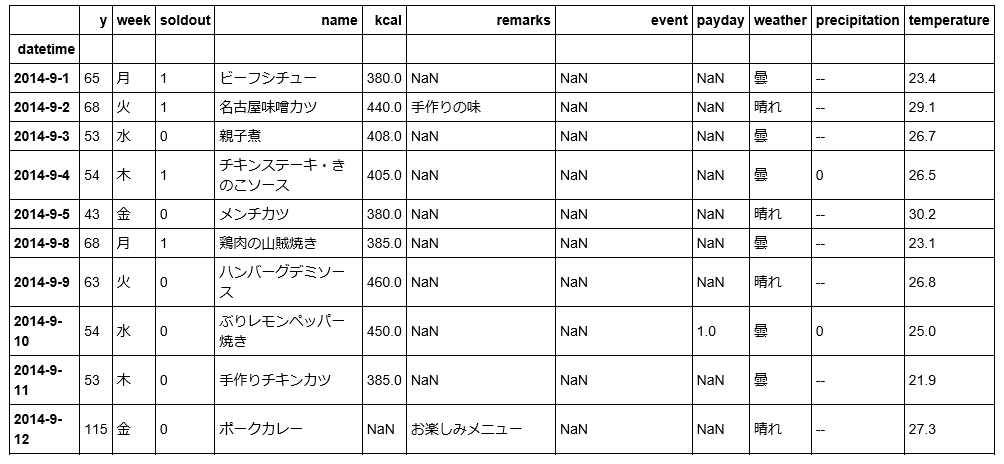
左から二列目の「y」というのが「売り上げ数」であり、今回予測したい対象です。
列名を見てみると、
「datetime:日付」
「kcal:カロリー」
「name:メインメニューの名前」
「temperature:気温」
などのデータが入っています。これらを使って売り上げを予測します!
課題内容やデータの詳細はSIGNATEのページで確認できます!
「SIGNATE」 お弁当の需要予測
https://signate.jp/competitions/24
☆どんな手順で予測モデルを作るの?
分析の手順は大きく分けて以下の通りです。
=======================
①前処理:データが埋まっていないところ(欠損)の補完や、より良いモデルを作成するためデータを加工する。
②モデル作成:機械学習アルゴリズムに前処理したデータを投入して予測モデルを作る。
③評価:予測結果の精度を数値で確認する。
=======================
☆使用言語
使用言語はPythonです。
10月時点でPython歴は3ヶ月でしたので、最初は何か動かしたくても書き方がわからないことが頻繁にありました…。
文法を調べつつ機械学習も勉強するという進め方でなんとか乗り越えました!
機械学習に関する便利機能がまとまっているscikit-learnライブラリを主に使用しました。
◆SIGNATE課題へのアプローチ
☆OJTのスタート!
初回はY.Sawaiさんが簡単な分析を行い、そのソースコードを見せてもらいながら説明していただく形でOJTが始まりました。
わかりやすい身近な例えで説明してくれたり、ホワイトボードに図解をしてくれたり、
ひとつひとつとても丁寧に教えてくださるY.Sawaiさん。
初めは「あまりの出来の悪さに見放されたらどうしよう…」と不安もありましたが、安心して取り組むことが出来ました!
☆心に残る、Y.Sawaiさんの教え7選
全てお話すると膨大な量になってしまうので、心に残ったY.Sawaiさんの教え7選を紹介したいと思います!
▶【その1.】「回帰か分類か確認せよ!!」
1番初めに確認することがコレ。機械学習の中にも種類があります。
今回の場合は「教師あり学習」といい、正解となるデータが存在する場合に用いられる手法です。
そして教師あり学習で解ける問題は大きく分けて「分類」と「回帰」があります。
回帰と分類で使うアルゴリズムも変わってくるので、最初に確認することが必要です!
[su_note note_color=”#F5D0A9″ text_color=”#000000″ radius=”3″ class=””]・分類:「動物の種類」や「YesかNoか」などデータが属するクラスを予測する問題
・回帰:「年齢」や「金額」などの連続量、数値を予測する問題[/su_note]
⇒今回は、お弁当の「売上数」を予測する問題なので、回帰問題ですね。
▶【その2.】「trainデータとtestデータに分けよ!!」
さてモデルを作ろう!…といってもいきなり全てのデータでモデルを作ってしまうと、モデルの答え合わせに使うデータがなくなってしまいます!
そのためデータは予め二つにわけておく必要があります。
[su_note note_color=”#F5D0A9″ text_color=”#000000″ radius=”3″ class=””]・trainデータ:予測モデルを作成するための学習用データ
・testデータ:予測モデルがどのくらい正解するか調べるための答え合わせ用データ[/su_note]
SIGNATEでは既にtrainデータ、testデータがわけられた状態でデータもらえるのですが、
実務でデータ分析をする際は、
「〇割は学習に使い〇割はテストに使うぞ」と初めに必ずわける作業が必要になります。
▶【その他3.】「前処理では、とにかく数値に直すこと!!」
いきなりデータをアルゴリズムにつっこむ前に、データを綺麗にしてあげる処理「前処理」が必要です。
モデル作成ではこの前処理がとても大事な部分…!
具体的にどんなことをするのかというと、
[su_note note_color=”#F5D0A9″ text_color=”#000000″ radius=”3″ class=””]・欠損処理:データが入っていない部分を埋めるまたは捨てる
・カテゴリ化:文字列のデータをカテゴリにわけて数字で表す。[/su_note]
などなど。
前処理とは「とにかく数値に直すこと!」です。
データに空欄があったり、文字が入っていたりすると上手くモデルが作成出来ないからです。
今回は
- カロリーの欠損を平均で埋める。
- メニュー名は文字列且つカテゴリ分けしにくいため捨てる。
などを行いました。
▶【その他4.】「OneHotが超重要!!」
さて、文字列を全部数字で表しました。
しかしモデル作成の前にもうワンステップ必要です。
同じ数字でも、降水量やカロリーといった「量的数値」と
「カテゴリ番号」では数字の持つ意味が変わってきます。
例えば、月~金までを1~5の数字に置き換えたとしても、アルゴリズムによっては「量的数値」と見なしてしまい
「月曜は小さく、金曜は大きい」という学習をしてしまいます。
そこを解決するのがOneHot処理です。
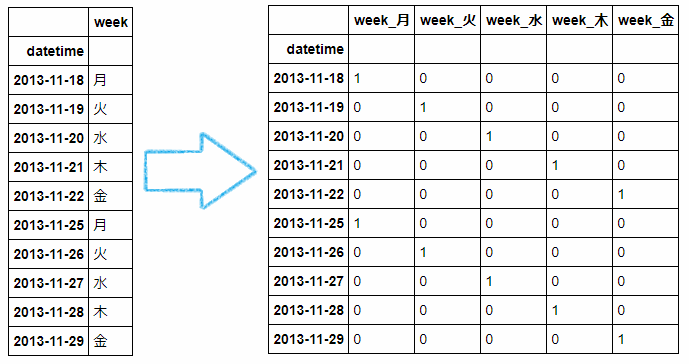
図のように月から金までを別々の要素として、0か1で表すようにすれば、
「1~5」の数字で表していた時のように数字の大きさに左右されることはなくなります。
▶【その他5.】「軸となるモデルを作成せよ!!」
さて、いよいよモデル作成に入ります!
いきなり複雑な分析は行わず、まずは軸となるモデルを作成します。
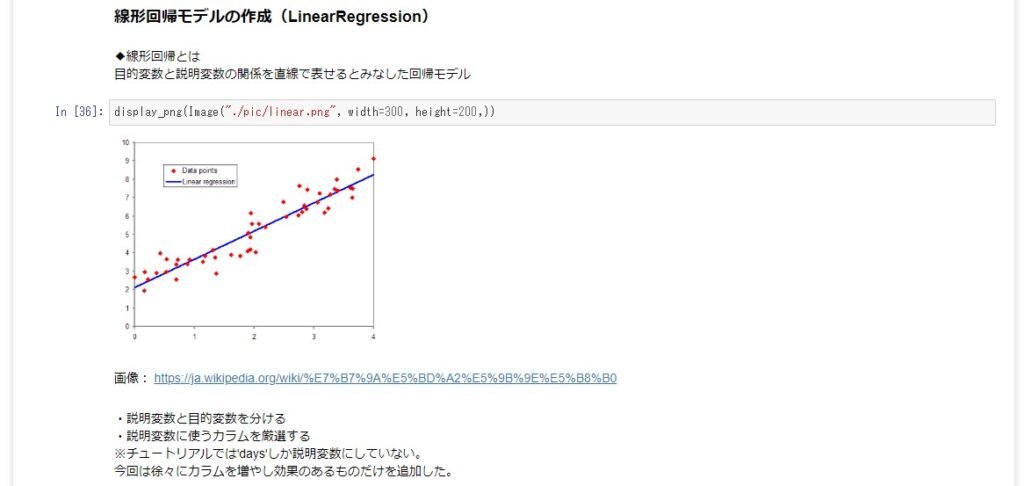
今回の課題は「売り上げと経過日数に大きな関係がある」ようです。
まずはグラフで確認してみます。
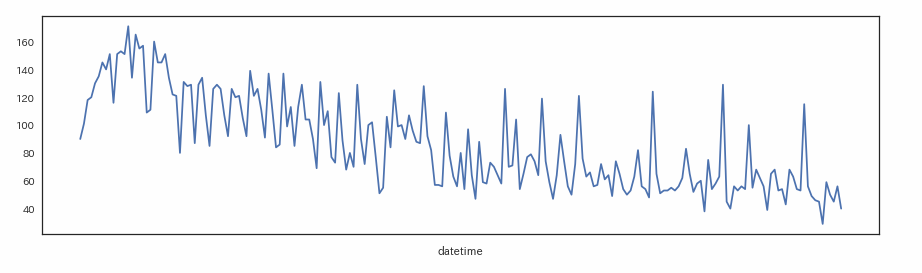
上下に動きがあるものの、全体的には日付が経つにつれて売り上げ数が減っています。
これを「売り上げ数と経過日数に線形な関係(直線で表せる関係)がある」として、データに手を加えていきます。
まず、日付形式のデータだとモデルに上手く学習してもらえないので数値に直す必要があります。
お弁当を売り始めて何日経ったか表す「経過日数」の列を作りました。
単純に1からの連番が入った列を作ればOKです。
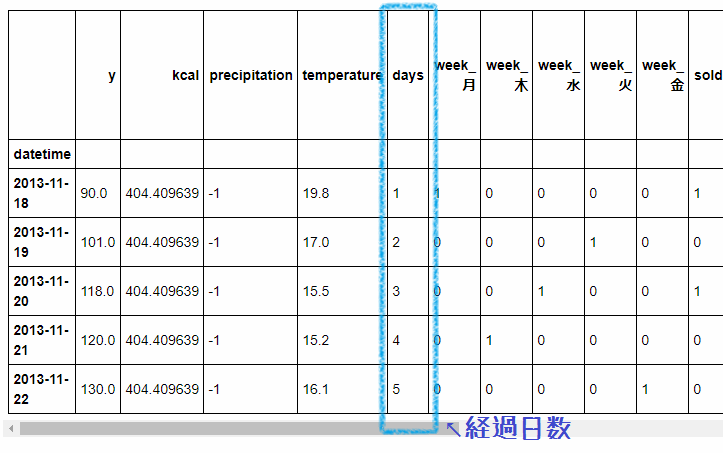
そして、線形回帰のアルゴリズム、LinearRegressionに学習させてモデルを作りました。
このモデルを軸にして、徐々に調整をしていきます!
▶【その他6.】「評価指標に注目せよ!!」
モデルが完成したら実際にtestデータを予測させ、結果をSIGNATEに提出します。
数秒でモデルの精度が算出され、コンペ参加者ランキングに反映されます!
では、モデルの精度はどんな評価指標で点数化しているのでしょうか?
予測モデルの評価指標は様々ありますが、今回の課題はSIGNATEの方で
「RMSE」という評価指標を使うと決められています。
「RMSE(Root Mean Squared Error)」とは、訳して「平均二乗平方根誤差」。
「実際の数値と予測した数値の誤差を二乗して絶対値をとったもの」です。
簡単に言えば「予測値が正解とどれくらい乖離しているか示すもの」なので、
0に近いほどモデルの精度が高い!
とにかく小さければよい!
ということになります。
この時点ではRMSEは20程、順位は1000位付近でした。
▶【その他7.】「データから想像せよ!!」
この後からは私とY.Sawaiさんはそれぞれでモデル作成をすることになりました。
しかし自由に自分で工夫をしようとしても何をしたらよいのかわかりません。
そこで、Y.Sawaiさんに「データを加工するとき、どこに注目しているのか」考え方のヒントをもらうことにしました。
Y.Sawaiさん曰く、データから「想像」をするのがポイントとのこと。
たとえば欠損している部分がある場合、
「なぜ、欠損しているのか?」
をまず考えるそうです。
欠損している部分だけ取り出して見ると「〇日以前は欠損している」ことがわかるとします。
すると「途中から記録し始めたデータなんだろう」と想像できます。
その上で欠損を埋めるべきか切り捨てるべきか決めていきます。
欠損は無意味なものではなく「欠損している」という情報を持った
貴重なデータなんですね!
また他の例では、
「一般的に雨の日は外食しに行く人が少ないからお弁当が売れるだろう」
という仮説を立て、雨の日だけを取り出して売り上げを見ます。
そして、実際に売り上げが大きければ「雨」の日を
重要な要素として扱うといった方法も教えてもらいました。
今までデータを眺めていても「データやな…」という貧相な感想しか
出てこなかった私はどんな風に工夫をしていいかわかりませんでした。
そのため、この「データから色々想像する」というアドバイスは、
オリジナルの工夫をするための大きな助けとなりました!
☆一か月取り組んだ結果…!
それから試行錯誤を続けて一か月…RMSE8.5まで下げることが出来ました!!
さらには28位のY.Sawaiさんを抜いて22位にランクアップ…!
特に、データを効果のあるものだけに選別してモデルを作成すること、
モデルを二つ組み合わせてより詳細な分析をすることが効果的でした。
◆成果発表会
SIGNATEで取り組んだ内容について、社内で成果発表会を行うことになりました。
ちなみにY.Sawaiさんには「成果発表会までに順位抜きます」と宣戦布告をされました。
プライドをかけた戦いも始まりつつ、社内発表の準備にかかりました。
はじめは部内のちょっとした知見共有会になると思っていたのですが、
他部署にお知らせしたところ、たくさん人が集まり10人以上の前で発表することに!!
機械学習はホットな分野なのだと改めて感じました。
技術的な内容を専門外の人にも伝えるというのはとても難しく、発表は苦労しましたが、自分の学びを振り返ることができ、とてもいい経験になりました。
そしてY.Sawaiさんには、ばっちり発表日までに順位超えられました。流石です…。
発表資料は以下に掲載しています。
(分析方法の詳細もわかります!)
Github :jupyter note book
https://mfieldeslab.github.io/MS_DataMining/
◆大変だったところ、今後に向けて
OJTの中でぶつかった壁は、大きく4つありました。
[su_note note_color=”#F5D0A9″ text_color=”#000000″ radius=”3″ class=””]・データを絞り込んでグラフや図で見たいけれど書き方がわからない
・データをどう加工すると良さそうか思いつかない
・試してみたけれど効果が得られなかったことに対して「なぜ効果が出なかったのか」を明らかに出来ない
・学んだ知識を人にわかりやすく伝えるのが難しい[/su_note]
上2つの壁については、OJT期間の中でも改善されていったので、
経験や知識をつけることで克服していけると感じました。
今後大きな課題になるのは下2つだと思います。
SIGNATEではスコアだけを追求すればよいので、
学んだ手法を片っ端から試して、スコアが良ければ採用していく、という形をとっていました。
しかし、これが実務の場合では、なぜその手法を使ったか理由と根拠を明確にして説明が出来なければいけません。
今後は、ただ覚えた方法を試すだけでなく
「こんなケースにはこんな手法が効く!」
というノウハウも貯めながら、人に説明するアウトプットの力もつけていきたいと思います。
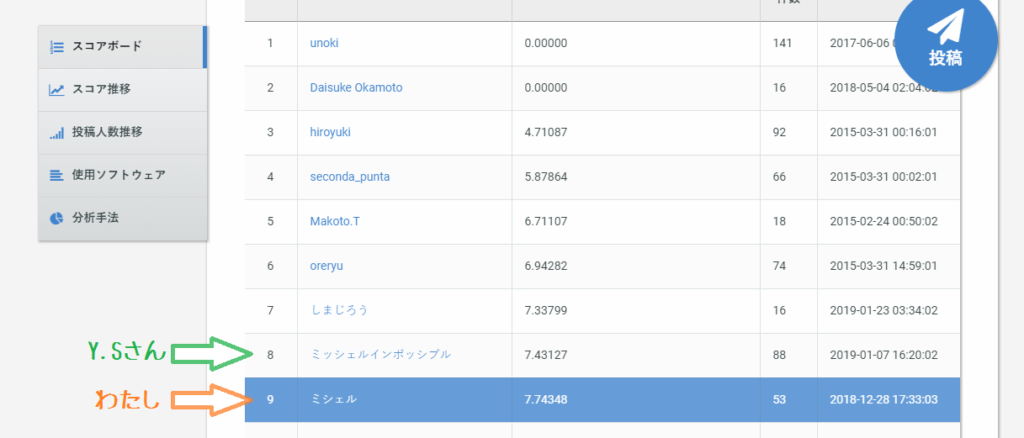
※ちなみにY.Sawaiさんとは発表後もバトっていて、
抜かし抜かされつつ2019年2月9日現在では8位と9位(2070人中)まで上り詰めました。




