*本記事は旧TechblogからCOLORSに統合した記事です。
目次
はじめに
*本記事は旧TechblogからCOLORSに統合した記事です。
この記事はSQL「データの前処理をしてみた」シリーズの第2回です。
———————-
※「第1回」は、以下を参照して下さい。
「第1回」データの前処理をしてみた <データインポート>
———————-
SQLを勉強したけど業務で使ったことがない方を対象に、SQLを使ったデータ分析での前処理を、部内のメンバーがリレー形式でお伝えしていきます。
自己紹介
2018年9月に中途で入社しましたS.Sと申します。
今までは市場調査業界でアンケート調査の企画や集計・分析を経験してきました。
SQLを今まで使ったことはありませんが、データ分析には欠かせない基礎的なツールですので、現在研修を通して習得に励んでいます。(研修3か月目)
今回のテーマ:データ利用範囲の確認
第1回ではCSV形式で保存されたテーブルをSQLでDBに取り込みました。
今回はその続きで、取り込んだテーブルの利用範囲を確認するSQLを紹介します。
————————-
・使用した環境
PostgreSQL 10.4
A5:SQL Mk-2
・前提
DBに複数テーブルをインポートした
————————-
本題
今回は複数のテーブルがあるケースで、各テーブルにレコードがどの程度またがって存在するのかを確認していきます。
日常業務においてテーブル間で同一サンプルのレコードがあるのか確認することは多々あるかと思います。
またデータ分析のコンペ等に参加して教師あり学習で予測をする際にも、関連テーブルにレコードがあるか、訓練データとテストデータで関連テーブルにレコードをもつ割合に差はないか、といったことを把握しておくことは大切です。
今回ですが、対象とするテーブルは下のような関係を持っているとします。
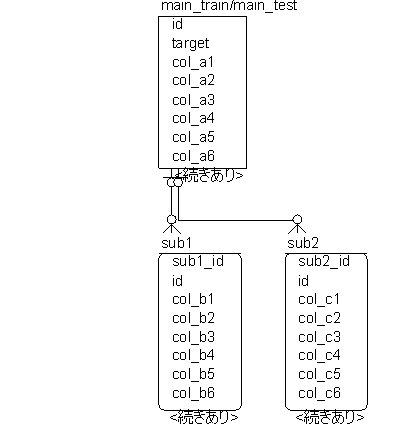
・main_train/main_test:メインテーブルで、主キーはidというカラムです。
・sub1/sub2:関連テーブルで、メインテーブルに対して補足的な情報を持っています。idというカラムでメインテーブルと紐づいています。
メインテーブルと関連テーブルのidを突き合わせることで、メインテーブルに存在するidが関連テーブルにどれくらい含まれているかを確認していきます。
今回の突き合わせ作業ですが、次の手順で進めていきます:
- 確認したいテーブルの全idを重複なしで抽出
- 「1.」で抽出した全idに対して、どのテーブルから抽出されたのかidごとにフラグを立てて確認
- 「2.」のフラグを集約して、テーブル間でまたがって存在するレコードがどの程度いるのかチェック
では、順番にみていきます。
- 確認したいテーブルの全idを重複なしで抽出
UNIONを使って全テーブルのidをまとめて出力します。UNIONを用いることで重複を省いてSELECT文の結果を統合します。
[code lang=”sql”]
SELECT id FROM main_train
UNION
SELECT id FROM main_test
UNION
SELECT id FROM Sub1
UNION
SELECT id FROM Sub2;
[/code]
【出力結果1(最初の10件)】

2. 「1.」で抽出した全idに対して、どのテーブルから抽出されたのかidごとにフラグを立てて確認
「1.」で出力した全件idと一致することを条件に各テーブルを左側外部結合します。結合後の結果がNULLでなければ(=結合前の各テーブルにidがあれば)1を、そうでなければ0をフラグとして立てることで、各idがどのテーブルに存在するのかを確認できます。
[code lang=”sql”]
SELECT DISTINCT
t0.id
, CASE
WHEN t1.id IS NOT NULL THEN 1
ELSE 0
END AS main_train_flg
, CASE
WHEN t2.id IS NOT NULL THEN 1
ELSE 0
END AS main_test_flg
, CASE
WHEN t3.id IS NOT NULL THEN 1
ELSE 0
END AS sub1_flg
, CASE
WHEN t4.id IS NOT NULL THEN 1
ELSE 0
END AS sub2_flg
FROM
(
{「1.」のクエリ}
) t0
LEFT OUTER JOIN main_train t1
ON t0.id = t1.id
LEFT OUTER JOIN main_test t2
ON t0.id = t2.id
LEFT OUTER JOIN sub1 t3
ON t0.id = t3.id
LEFT OUTER JOIN sub2 t4
ON t0.id = t4.id;
[/code]
【出力結果2(最初の10件)】
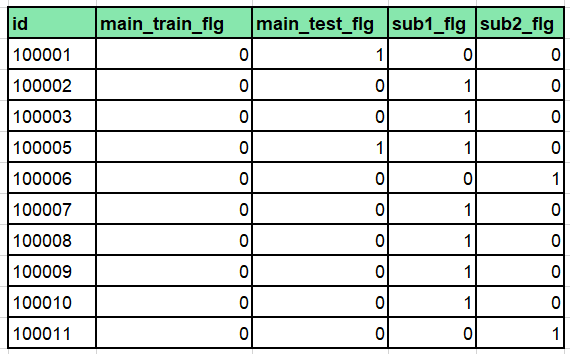
一番左の列が「1.」で全件出力したidリスト、その右側に並んでいる4列が外部結合で各テーブルから引っ張ってきたidに対応するフラグです。例えば、id ‘100001’ はmain_testのみに存在して、sub1とsub2テーブルにはないことがわかります。
3. 「2.」のフラグを集約して、テーブル間でまたがって存在するレコードがどの程度いるのかチェック
「2.」で付加したフラグをGROUP BY句で集約しレコード数を出します。出力結果を見やすくするためにORDER BY句でソートします。
【出力結果3】
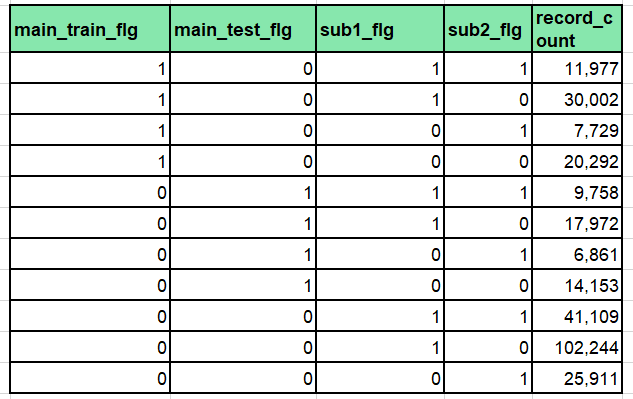
出力結果3から次のことがわかります。
・メインテーブル2種のどちらにも存在しないレコードが169,264件(出力結果2の下3行の合計件数)あります。これらのレコードは関連テーブルにしか存在しないサンプルですので削除してもよいでしょう。
・メインテーブル2種の関連テーブルへの分布をみると、割合はほぼ同じで大きな相違がありません(下表)。
main_trainテーブルを教師あり学習で使用し、訓練したモデルでmain_testテーブルのデータを予測するような場合は、この構成比があまりに大きくズレていると対応を考えなければなりません。
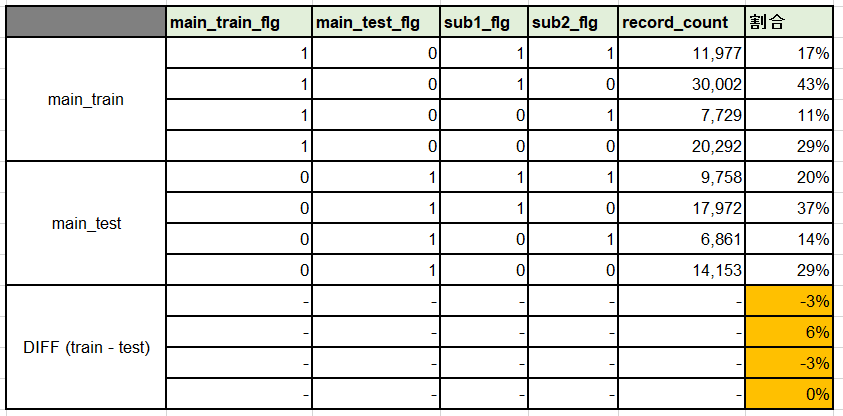
テーブル間のidを突合することで、複数のテーブルをまたいで存在するレコードがどの程度いるのか俯瞰することができました。今回はこれで終了です。
次回のSQL「データの前処理をしてみた」シリーズ第3回は、「サンプリング」をテーマにする予定です。
最初にざっくりとデータ全体を見たいのに、レコード数が多すぎてクエリの結果が返ってくるまでが長い・・・そんな時に選択肢の一つとなる処理方法をご紹介する予定です。
※「1.」~「3.」をまとめたクエリを記載します。「2.」の結果を中間テーブルで作成しています。
(第3回に続く)
(第1回)
「第1回」データの前処理をしてみた <データインポート>