*本記事は旧TechblogからCOLORSに統合した記事です。
こんにちは。株式会社エイアイ・フィールドのK.Tと申します。
現在、機械学習やディープラーニングを用いたレコメンドエンジンの開発に携わっています。
今回はcleanlabというノイズラベルの除去ができるPythonのライブラリを紹介したいと思います。
目次
- cleanlabとは
- 使ってみる
- データセットの準備とライブラリのインストール
- データセットの読み込み
- ノイズ画像の検出
- ノイズ画像の可視化
- まとめ
cleanlabとは
cleanlabはディープラーニングや機械学習で言う「ノイズ」となるラベルを多く含むデータセットを使って学習したり、データセットのラベルエラーを見つけたりするための機械学習Pythonパッケージです。
以下のレポジトリで公開されています。
機械学習やディープラーニングの学習に用いるデータセットは人の手でラベル付けされますが、その中には間違えてラベル付けされたデータや、他のラベルと間違えやすい紛らわしいデータが含まれていることがあります。このようなデータはノイズとなり、モデルの学習に悪影響を与えます。cleanlabを使うことでデータセットの中からノイズとなりうるデータを見つけ出すことができます。
使ってみる
今回はこちらで公開されているThe Quick Draw Datasetを用いてcleanlabを試してみます。このデータセットはGoogleが機械学習の研究用に公開しているゲーム Quick, Draw! をプレイしたユーザーが書いた手書きの絵のデータです。今回はデータセットのうち dog, cat の2種類の画像を識別するタスクを想定し、認識の際にノイズとなるデータを検出してみます。
動作環境にはGoogle Colaboratoryを使用しました。
データセットの準備とライブラリのインストール
データセットの準備とライブラリのインストールを行います。
%%bash mkdir data gsutil -m cp \ "gs://quickdraw_dataset/full/numpy_bitmap/cat.npy" \ "gs://quickdraw_dataset/full/numpy_bitmap/dog.npy" \ data pip install cleanlab
データセットの読み込み
ライブラリをインポートし、データセットの読み込みを行います。
import glob, os, random
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.layers import Input, Conv2D, Flatten, Dense, MaxPooling2D, Activation
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import StratifiedKFold
import cleanlab
from cleanlab.pruning import get_noise_indices
def seed_everything(seed=0):
#乱数の固定
random.seed(seed)
np.random.seed(seed)
tf.random.set_seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
os.environ['TF_DETERMINISTIC_OPS'] = '1'
seed = 0
seed_everything(seed)
ダウンロードしたデータセットを読み込んで表示してみます。
dog = np.load('data/dog.npy')
cat = np.load('data/cat.npy')
print(dog.shape, cat.shape)
fig, ax = plt.subplots(1,2, figsize=(8,5))
ax[0].imshow(dog[0].reshape(28,28), cmap='gray')
ax .imshow(cat[0].reshape(28,28), cmap='gray')
.imshow(cat[0].reshape(28,28), cmap='gray')

犬画像データは152159枚、猫画像データは123202枚あるようです。
ノイズ画像の検出
cleanlab を使用して犬画像と猫画像の分類時にノイズとなる画像を検出してみます。cleanlabを使用するためには分類モデルを構築し、モデルの予測結果と真のラベルの値をcleanlabに渡す必要があります。まずは犬画像、猫画像のラベルをそれぞれ0, 1としてクロスバリデーションを行い、各foldの検証画像に対する予測結果を用意します。
#データ準備 images = np.concatenate([dog, cat]) images = images.reshape(images.shape[0], 28,28, -1) images = images / 255.0 labels = [0 for _ in range(dog.shape[0])] #犬画像=0 labels +=

各画像に対する予測結果が用意できたら、cleanlab の get_noise_indices 関数を使用します。
以下のように各クラスの予測確率、真のラベルをそれぞれ渡すことで、ノイズであると判定されたデータのインデックスを取得できます。sorted_index_method=’normalized_margin’ を指定することでノイズである可能性が高いデータの順で結果を取り出せます。
# cleanlab によるノイズ画像の検出
psx = np.array(oof_pred)
s = np.array(oof_labels)
ordered_label_errors = get_noise_indices(
s=s,
psx=psx,
sorted_index_method='normalized_margin', # Orders label errors
)
ノイズ画像の可視化
ノイズであると判定された画像を可視化してみます。まずは最もノイズである可能性が高い画像から。
# 元画像におけるノイズ画像のインデックス
noise_idx = np.array(oof_idx)[ordered_label_errors]
# ノイズ画像の表示
print(f'Most noisy label: {labels[noise_idx[0]]}')
plt.imshow(images[noise_idx[0]].reshape(28,28), cmap='gray')
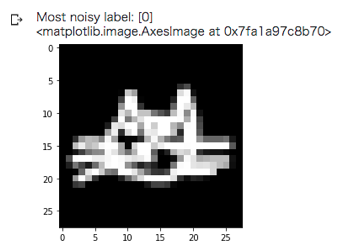
ラベルは犬画像(=0)ですが、どう見ても猫の画像ですね。。。
他のノイズ画像も表示してみます。
def show_images(images, labels):
fig, ax = plt.subplots(2, 10, figsize=(10,10))
ax = ax.flatten()
idxs = np.random.randint(0, len(images), 20)
for i, idx in enumerate(idxs):
img = images[idx]
if len(img.shape) != 2:
img = img.reshape(28,28)
label = labels[idx]
ax[i].imshow(img, cmap='gray')
ax[i].set_title(f'label: {label}')
plt.show()
noise_images = images[noise_idx]
noise_labels = labels[noise_idx]
show_images(noise_images, noise_labels)

ぱっと見ても明らかにラベルが逆だったり、犬か猫かわからない画像ばかりですね。。。
ノイズ画像はうまく検出できているようです。
まとめ
今回はcleanlabを用いてノイズ画像の検出を行ってみました。一枚一枚画像を確認して手動でノイズ画像を取り除くのは手間がかかりますが、cleanlabを使うことでお手軽にできそうです。モデルの予測結果とラベルの値さえあれば使用できるため、フレームワークによらずに使用できる点も便利だと思います。cleanlab はICML2020に投稿された [1911.00068] Confident Learning: Estimating Uncertainty in Dataset Labels という論文の実装となっています。どのような仕組みでノイズデータを検出しているかが気になる方はチェックしてみてください。私も仕組みまで理解できていないのでチェックしたいと思います。