*本記事は旧TechblogからCOLORSに統合した記事です。
はじめに
はじめまして。エイアイ・フィールドに2020年5月より中途入社いたしました、K.Higaと申します。
前職では商品の出荷予測アルゴリズム構築を、1人黙々と行なっておりました。
機械学習モデルやディープラーニングを用いて予測や分類をしたりという経験はある程度あったのですが、データアナリシスの経験はあまりなく、今回の課題にチャレンジしております。
課題内容
株式会社Agoop(https://www.agoop.co.jp/)が無償提供(2020年5月現在)している、2020年1月〜4月の各地人流データ」と「2020年1月〜4月のコロナウイルス感染者報道」のデータを分析し、なにかしら知見が得られないかという研修課題でした。
実行環境など
実行環境: google colaboratory
使用ライブラリ:
pandas 1.0.3
scipy 1.4.1
seaborn 0.10.1
matplotlib 3.2.1 など
google colaboratoryは構築不要の仮想開発環境で、自分の環境に依存しないという点で、非常に重宝させていただいています。先日、友人にデータサイエンスを勉強したいという相談をされた際にも、環境構築のコストがフリーなので強くオススメしました。制限はありますが無料でGPUやTPUが使える点も、魅力だと思います。
社内でミニプレゼンテーションをした際にも、colabで作成したノートブックでプレゼンしました。
データの確認
pandasを用いてデータの中身を確認しました。pandasとは、表データを分析するのに非常に便利なライブラリのことです。列・行単位の様々な変換やデータ内容の閲覧など、様々なことが行えます。

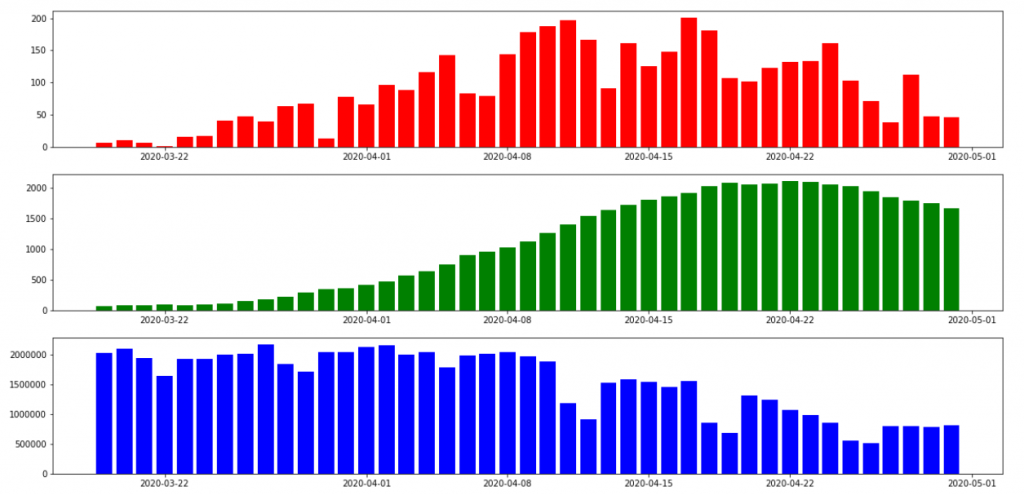
人流データにはお台場等、各地域の時間毎人口データがありました。
コロナウイルス感染者報道データには、東京の日別公表者数データがありました。
人流データ

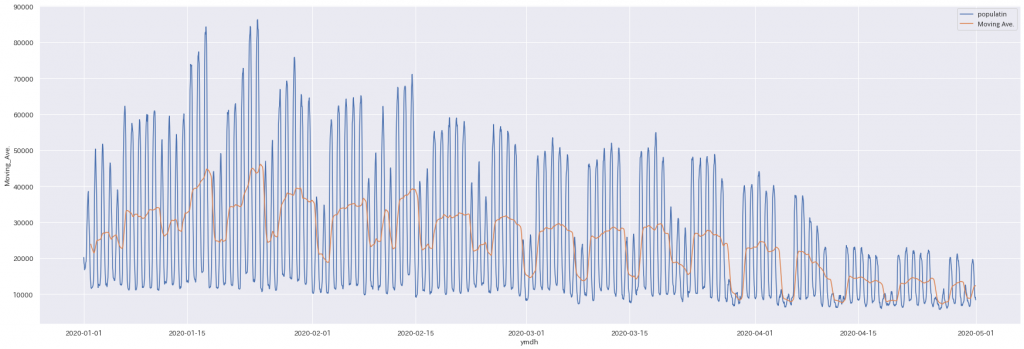
各地域の人流データを、seabornでプロットしました。seabornとは、matplotlibをベースとした、簡易操作ながらも美しいデータ描写ができるライブラリです。
上図は『お台場』の人流データです。青線が生データの時間別データのプロット、オレンジ線が24時間移動平均です。
『移動平均』が出てきたので、私の見解ですが、時系列データについて述べさせていただきます。
『時系列データ』の解釈ですが、私は2パターンあると思っております。
1つめは、『時間情報を含む(あるいは時間軸で並べられた)データ』です。今回の様な、時間毎人流数というようなデータです。世間一般のイメージはこちらに当てはまると思います。
2つめは、『以前(または以降)の時点が、現在・未来に影響を及ぼすデータ』です。これはどちらかというと機械学習や統計学的な立場からの見解です。
どちらにせよ、時系列データを分析するには『移動平均』という概念が便利です。生データはギザギザしていて、一見人流が増えているのか減っているのか、傾向がわかりにくいです。なぜギザギザしているかというと、月(1月なのか2月なのか)・週(第1週なのか第二週なのか)・曜日(月曜なのか日曜なのか)・時間(日中なのか夜間なのか)といった、様々な要因が入り混じっているからです。24時間移動平均をとると、『時間(日中なのかどうか)』の要因が緩和され、少々滑らかな曲線(オレンジ線)に近づくわけです。まだ移動平均線にも周期的な変動が見られ、これは月や週・曜日の要因が残っていることを示しています。
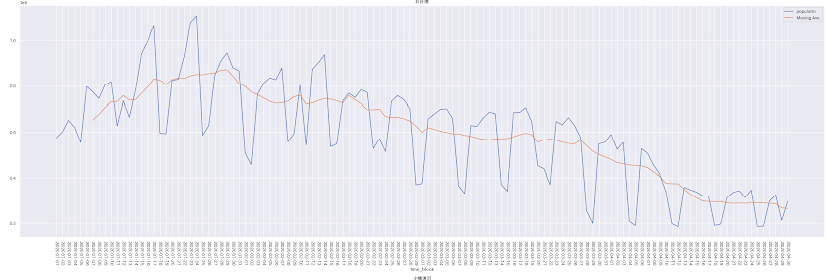
こちらの図は時間別を日別に整形した人流データのプロットと、7日間移動平均です。曜日の要因も緩和され、より見やすい曲線に近づいたと思います。移動平均を見ると、一月末から右肩下がりにダウントレンドなことがわかります。
こういった傾向値はARIMAXモデルの様な、構造時系列モデルとデータをフィッティングさせることでも得られます。
ARIMAXモデルとは、時系列データは『短期的自己相関 + 周期的要因 + トレンド + ランダム要因』という構造時系列モデルによって成り立っているという立場から、時系列データの自己相関をあぶりだしていく分析モデルです。データのラグにおける(偏)自己相関のスパイクの位置から、周期的要因が想像されます。
ただ、移動平均は単純な足し算・割り算でお手軽に計算でき、知見も十分得られますので、今回は傾向値として移動平均を採用しました。 コロナウイルス感染者報道データが日別ということもあり、人流データも日別で分析を進めることにしました。
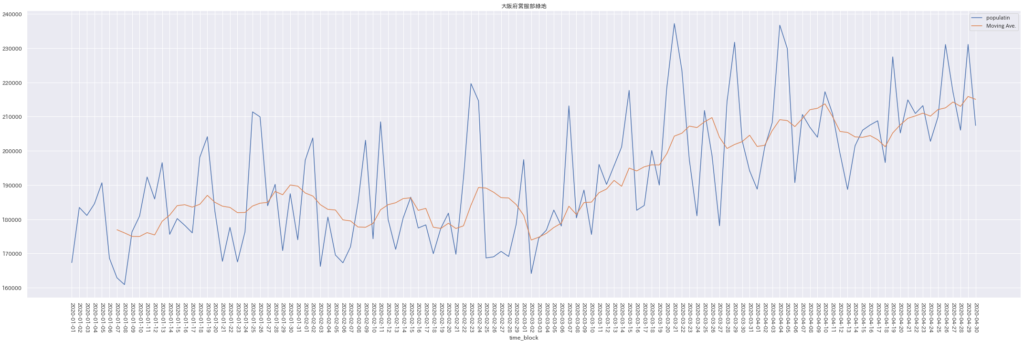
上図は『大阪府営服部緑地』の日別人流データです。お台場とは対照的に人流がアップトレンドなのが見て取れました。
その他の地域の人流データも見てみたところ、大阪府営服部緑地と片瀬西浜海水浴場は人流の下降傾向はみられず、その他の地域では下降傾向がみられました。
この下降傾向を今回はコロナウイルス感染者報道など、コロナウイルスにまつわる影響だと仮定します。この仮定は少々強引で、本当は昨年度との人流データ比較をしないといけないとは思うのですが研修課題ということもあったので、得られたデータ内と定性情報で仮定付けをしました。
コロナウイルス感染者報道
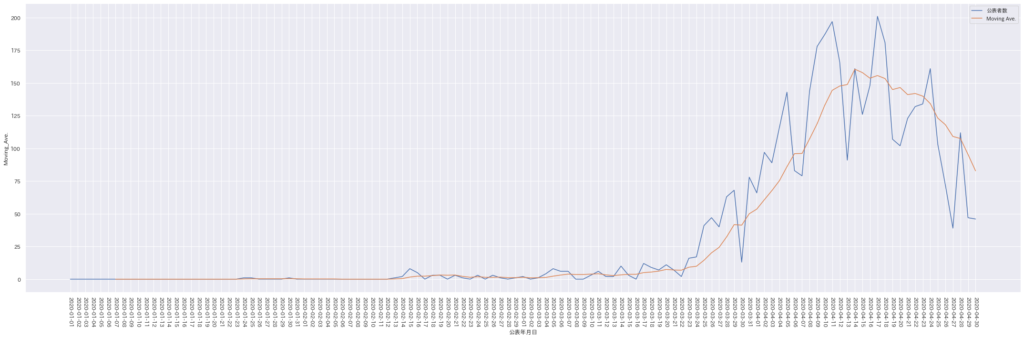
こちらは日別の報道感染者数とその移動平均です。3/24付近で上昇傾向が強まっていることがみて取れました。
テーマの設定
これらのデータから、何をテーマに設定しどんな知見を得たいかを設定します。
まずどちらのデータにフォーカスするかですが、人流データにしました。理由は、コロナウイルスの検査精度や件数は不確定な要因が多いからです。それよりは確実なデータである人流データを、まずは深掘りしようと考えました。
そして今回は、『どの時点から人流の異常下降が始まったといえるか』ということをテーマに設定しました。
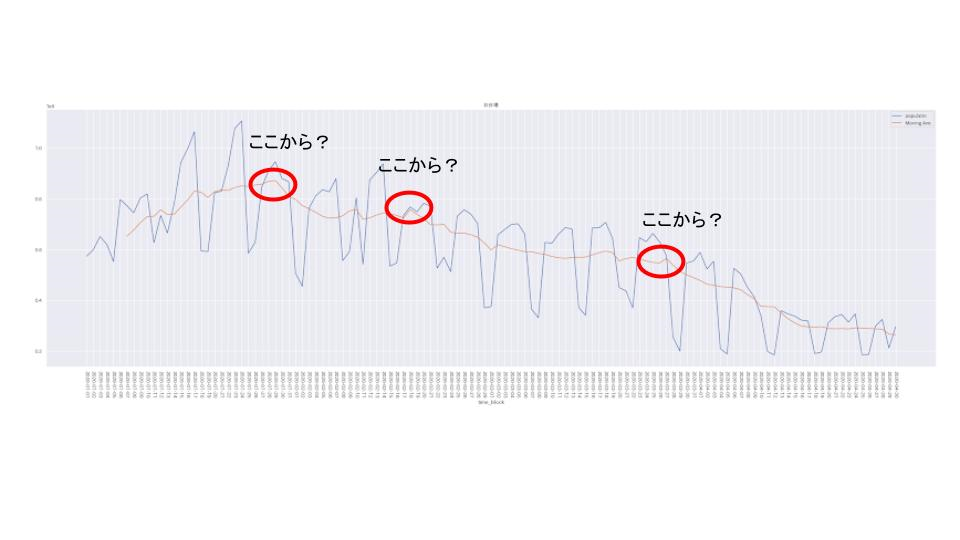
確かにデータを見ると、コロナウイルス要因で人流が下降傾向にあると言えます。ただし、どの時点からコロナウイルス要因により人流が異常下降し始めているのかということは、曖昧だと思います。(上図)
人流トレンド下降はコロナウイルスのせいという仮定をしているので、『この時点からは少なくとも、コロナウイルスの影響で人流が異常下降している』というその時点をなんとか明示できないかと考えました。
やったこと
スミルノフ・グラブス検定の応用
今回のテーマは、トレンドの異常下降時点を探るということです。これは異常検知と非常に似ていると考えました。
異常検知の手法は様々あり私もこの分野は勉強途中なのですが、手法の一つに外れ値検出があります。正常なデータの分布を想定しておき、各データがその分布に対して大きく外れているか否かを検討します。
この考え方を使って、現在(図の右側)から移動平均値が外れ値とはいえない時点まで遡れば、その時点が異常下降の分岐時点といえるのではないかと考えました。
外れ値の検出にはスミルノフ・グラブス検定(SG検定)を用いました。
SG検定とは、すべてのデータは同じ正規母集団から得られているということを帰無仮説(無に帰したい、否定したい仮説。帰無仮説を棄却することにより、主張したい対立仮説を採用します)におき、端の値を検定することで外れ値を特定する手法です。次々に端の値を検定し、帰無仮説が棄却できなくなるまで繰り返すと、外れ値除去ができます。
短い期間であれば移動平均値は正規分布に従うと考え、SG検定で外れ値と言えなくなるまで遡ってみました。
結果を申し上げると、この手法はうまくいきませんでした。かなり寛容に検定したようで、思う様に外れ値を検出できませんでした。
カーネル密度関数の応用
次に考えたのは、ガウシアンカーネルの利用です。正確に記述すると、ガウシアンカーネルを用いたカーネル密度推定を利用するという表現になります。
各データにある広がり(カーネル関数)を定義し、それを足し合わせてデータ全体の分布を推定する手法です。その「広がり」にガウス分布を採用しているということです。
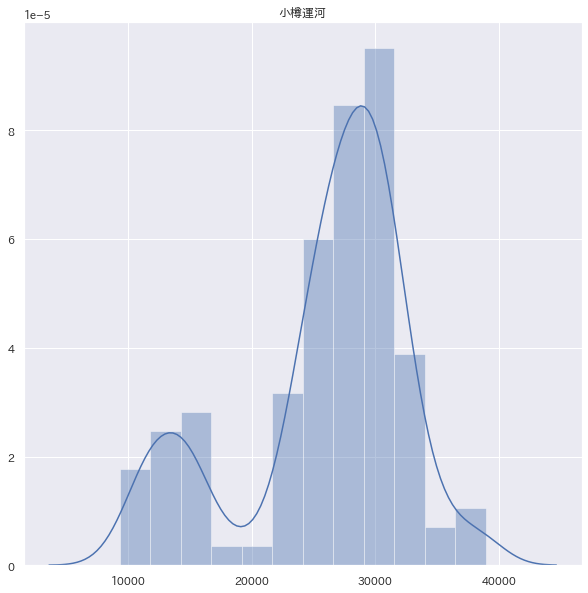
例えば上図は小樽運河の移動平均値のヒストグラムです。これをみると集団がふたこぶラクダの様になっています。
このようなヒストグラムの場合、二つの性質の違う集団が含まれている可能性があるといえます。このうち、移動平均値が小さい集団(赤色)を、異常下降グループとみなすこととしました。
(余談ですがラクダ関連でひとつ・・・。ラクダとヒトの濃厚接触により感染するコロナウイルスがあるそうです。MERS【https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/kenkou/kekkaku-kansenshou19/mers.html】)
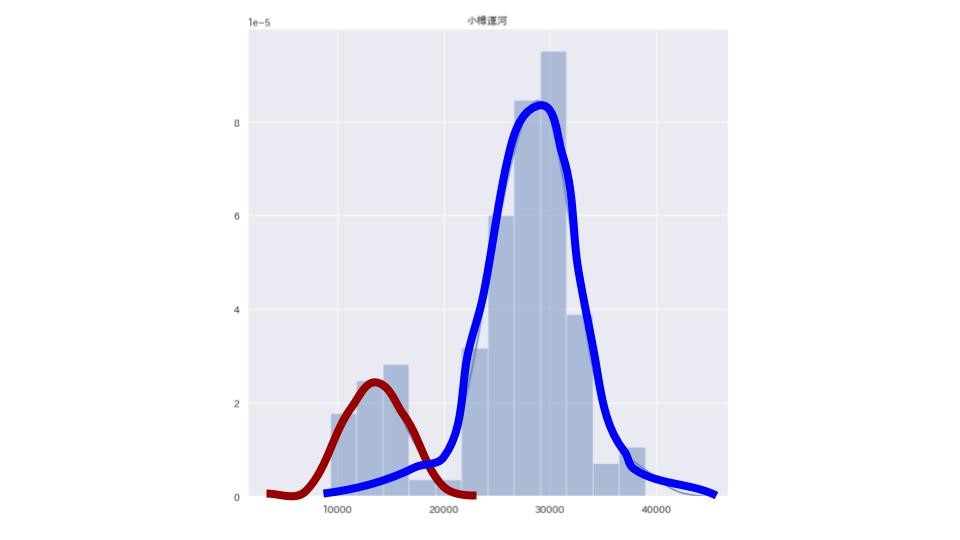
scipy.stats.gaussian_kdeでガウシアンカーネルを用いた密度推定を行い、小さい集団の平均・分散を適宜仮定しました。
その後、最近から遡りどこまでが小集団の値に該当するかを確認しました。
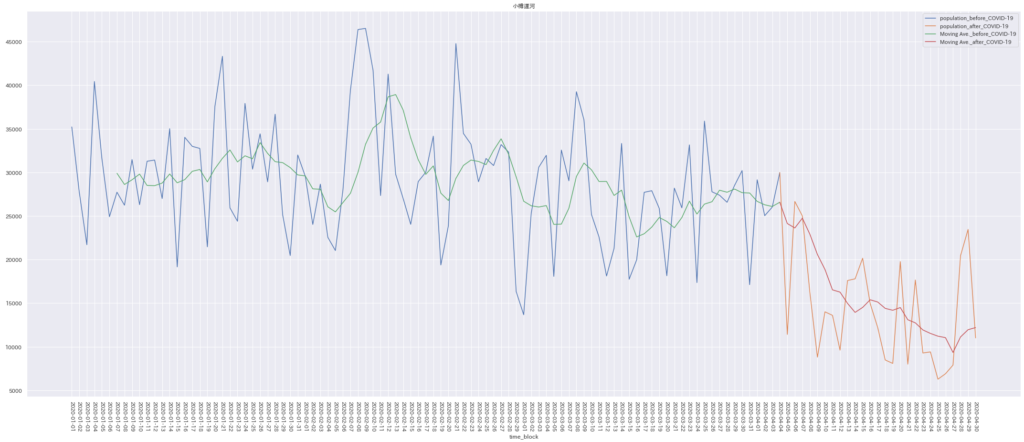
上図の赤色線がその範囲に該当しており、4月4日〜でした。
他の地域についても同様の処理を行ない、以下の知見が得られるのではないかと考えられました。
- 東京・神奈川は03/24~3/29、北海道は04/04、京都は04/10から異常下降が始まる。
- 東京から距離がある地域は、東京でのトレンド異常下降発生後6日間~17日間のラグの後、異常下降が始まると推測できる。
また、東京の日別感染者数のトレンドは3/24付近で急上昇していますので、
- 東京の人流は、東京の感染者数報道に即座に反応し、異常下降が始まると推測できる。
ということもいえるのではないかと思います。
東京の感染者報道の影響は、東京では即座に人流データに影響し、それが1~2週間かけて地方へ伝搬していく。
これは例えば、人口の多い東京から各地域へヒト感染していくその感染速度が相関しているのではないでしょうか。また、遠く離れた場所で起きたことは時間がたつにつれて実感がわいてくるという、地理的距離からなる危機感のラグという心理的効果も相関しているのかもしれないと、想像されます。
各地域における感染者報道のデータも見てみないと一概には言えませんが、上記のような相関が背景として想定できました。
さいごに
研修課題の『人流データ』『感染者数報道』のデータをもとに、人流異常下降時点・地域ごとの異常下降時点のラグ・報道と人流との関連性を考察してみました。
ただ例えば、あらためてコロナの周辺情報を調べると3月24日は東京五輪延期が正式公表された日だそうで、こういった他要因も人流に大いに関わってきますが当分析では未考慮である点、人流の異常下降が起きなかった地域とそうでない地域との違い、ラグが発生した要因の深掘りなど、つっこみどころが多くあり、まだまだ分析すべき要素がたくさん眠っていると感じます。
少しでもこの記事が、皆様の参考になれば幸いです。