*本記事は旧TechblogからCOLORSに統合した記事です。
目次
- 前書き
- Google Colaboratory での YOLOv3 の学習
- 学習実行
- 学習状況の確認
- 学習の中断と再開
- Google Colaboratory の使用制限への対策
- loss 値の確認
- 精度確認
- テスト画像で物体検出
- まとめ
前書き
こんにちは。株式会社エイアイ・フィールドのK.Tと申します。
前回に引き続き、ディープラーニングによる物体検出モデルの作成を行っていきます。前回の記事では物体検出モデル作成のための学習データを用意しました。 今回は Google Colaboratory を用いて、 YOLOv3 のモデルの学習を行っていきます。
Google Colaboratory での YOLOv3 の学習
Google Colaboratory は無料で使用できるクラウド上のJupyter notebook 環境で、自分の PCに環境を作成せずともコードを書くことができます。GPU を使用することも可能です。
以下のページにアクセスし、メニューの ファイル->Python3 の新しいノートブック を選択し、ノートブックインスタンスを作成します。使用するには Google アカウントが必要なので、あらかじめ作成しておきます。
https://colab.research.google.com/notebooks/welcome.ipynb?hl=ja
ノートブックインスタンスを作成したら 上部メニューの 「ランタイム」 ->「ランタイムのタイプを変更」 を順に選択し、「ハードウェアアクセラレータ」 を GPU に変更します。これで 学習時に GPU を使用することができます。

次に前回の記事で作成した設定ファイルと画像のzipファイルを Google ドライブにアップロードしておきます。
アップロードが終わったらGoogle ドライブをマウントします。ノートブック上で以下のコードを実行し、表示されるURL先に表示されるパスワードを入力すると Google ドライブをマウントし、ドライブ内のファイルを使用できるようになります。
from google.colab import drive
drive.mount('/content/drive')
次に以下コマンドを順に実行し、darknet の使用準備とドライブから学習用データのコピーを行います。
# darknetのクローン ! git clone https://github.com/AlexeyAB/darknet.git # MakeFile を GPU 使用設定に書き換えてコンパイル %cd /content/darknet !sed -i 's/GPU=0/GPU=1/g' Makefile !make # ファイルをドライブからコピー # /content/drive/My Drive/My Drive 以下は各自設定に合わせて変更 ! cp '/content/drive/My Drive/blog_data/setting_files/train.txt' . ! cp '/content/drive/My Drive/blog_data/setting_files/valid.txt' . ! cp '/content/drive/My Drive/blog_data/setting_files/classes.txt' . ! cp '/content/drive/My Drive/blog_data/setting_files/yolov3-voc.cfg' . ! cp '/content/drive/My Drive/blog_data/setting_files/datasets.data' . ! cp '/content/drive/My Drive/blog_data/setting_files/train_img.zip' . ! cp '/content/drive/My Drive/blog_data/setting_files/valid_img.zip' . # 画像フォルダの解凍 ! unzip train_img.zip ! unzip valid_img.zip
次にモデル学習に使用するweightsファイルをダウンロードします。weights ファイルにはさまざまな物体の特徴を学習した YOLO モデルのパラメータが保存されており、これを使用することで学習時間を短縮できます。
# 事前学習済みweightsファイルのダウンロード !wget https://pjreddie.com/media/files/darknet53.conv.74
以上で darknet フォルダ内に必要な画像と設定ファイルのコピーが完了し、学習の準備が整いました。
学習実行
以下のコマンドで YOLOv3 の学習を実行します。学習を実行するとログが大量に出力され、放置するとブラウザの動作が重くなるため、 train_log.txt にリダイレクトして出力しています。
# 学習実行 # コマンド形式: darknet detector train <data> <cfg> <weights> !./darknet detector train datasets.data yolov3-voc.cfg darknet53.conv.74 >> train_log.txt
エラーになる場合は以下の点をチェックしてみてください。私が学習実行時に遭遇したエラーの原因は以下のうちのいずれかでした。
・各設定ファイルの記述(ファイルパスなど)が正しいか
・yolov3-voc.cfg の batch, subdivisions の値を調整
・各設定ファイルの文字コード、改行コードの見直し
・Notebook のGPU 設定
学習状況の確認
学習の状況はdarknet フォルダに出力される train_log.txt に出力されます。

ログにはエポック数ごとの学習状況が出力されます。学習がうまく進んでいるかは loss の値を確認します。loss は損失関数の値を表しており、この値が次第に減少していれば学習がうまく進んでいます。

loss の値が十分に小さくなるまで学習を続けます。リポジトリの説明によると 小さいデータセットなら0.05、大規模なデータセットなら3.0くらいまで下がるまで学習させるとよいそうです。
今回はデータ数が少ないため、0.05くらいを目安にしてみます。学習には時間がかかるのでのんびり待ちましょう。
学習の中断と再開
学習を中断する場合は実行中セルの左端のボタンを押すとdarknetの動作を停止できます。
モデルの学習状況は datasets.data のbackup で指定したフォルダに自動で保存されます。
今回はdarknet/backup フォルダに以下の名前で自動で保存されます。
- yolov3-voc_last.weights:100エポックごとに自動保存
- yolov3-voc_<エポック数>.weights:1000エポックごとに自動保存
学習を中断後、再開する場合は保存されたweights ファイルを指定して darknet の学習コマンドを実行することで、中断した時点から学習を再開することができます。
# 保存されたweights ファイルを用いて学習実行 !./darknet detector train datasets.data yolov3-voc.cfg /content/darknet/backup/yolov3-voc_last.weights >> train_log.txt
Google Colaboratory の使用制限への対策
参考:https://qiita.com/enmaru/items/2770df602dd7778d4ce6
非常に便利なGoogle Colaboratory 環境ですが、以下の条件を満たすとノートブックの状態がすべてリセットされ、保存されたweightファイルが失われてしまいます。(2019/1/25 現在)
- 新しいインスタンスを起動してから12時間経過
- ノートブックのセッションが切れてから90分経過
学習には時間がかかるため、これらの制限に対して対策を行う必要があります。1 に関しては12時間が経過する前に学習を中断し、weightsファイルをダウンロードしたり、google ドライブに保存することで対応できます。
# weights ファイルとログファイルをドライブに保存 !cp -r /content/darknet/backup '/content/drive/My Drive/blog_data/setting_files/' !cp train_log.txt '/content/drive/My Drive/blog_data/setting_files/'
2 については以下の PowerShell スクリプトを実行し、1時間毎にノートブックに自動でアクセスすることでセッション切れを防止しました。
for ($i=0; $i -lt 1000000; $i++){
Write-Output ("count:"+$i)
# <url> を自分のノートブックの url に変える
iwr <url>
Start-Sleep -s 3600
}
iwr コマンド後の<url> を自分のノートブックの url に変更して上記スクリプトの拡張子を .ps1 にして保存し、右クリック->PowerShell の実行をクリックすると実行できます。これを実行しておけば、12時間が経過するまではノートブックを放置していてもOKになります。
loss 値の確認
ある程度学習を行ったら学習を中断し、lossの値を確認してみます。ログファイルを開いて確認してもいいのですが、以下の関数でログファイルから loss の値プロットしてみました。
import matplotlib.pyplot as plt
%matplotlib inline
def plot_yolo_log(logfile, xlim=None, x_scale=None, y_scale=None):
"""
ログファイルからlossの値をプロットする関数
logfile: ログファイルのパス
xlim: x軸の表示範囲をタプルで指定
x_scale: x軸のスケール
y_scale: y軸のスケール
"""
with open(logfile, 'r') as f:
lines = [line.rstrip("\n") for line in f]
numbers = {'1','2','3','4','5','6','7','8','9'}
iters = []
loss = []
fig,ax = plt.subplots()
prev_line = ""
for line in lines:
args = line.split(' ')
if len(args) < 4:
continue
if args [-1:]==':' and args[0] in numbers :
#print(args)
iters.append(int(args[:-1]))
loss.append(float(args
[-1:]==':' and args[0] in numbers :
#print(args)
iters.append(int(args[:-1]))
loss.append(float(args ))
if xlim:
ax.set_xlim(xlim)
if x_scale:
ax.set_xscale(x_scale)
if y_scale:
ax.set_yscale(y_scale)
ax.plot(iters,loss)
plt.xlabel('iters')
plt.ylabel('loss')
plt.grid()
ticks = range(0,250,10)
#ax.set_yticks(ticks)
plt.show()
plot_yolo_log("train_log.txt", xlim=(0, 4000), y_scale='log',)
))
if xlim:
ax.set_xlim(xlim)
if x_scale:
ax.set_xscale(x_scale)
if y_scale:
ax.set_yscale(y_scale)
ax.plot(iters,loss)
plt.xlabel('iters')
plt.ylabel('loss')
plt.grid()
ticks = range(0,250,10)
#ax.set_yticks(ticks)
plt.show()
plot_yolo_log("train_log.txt", xlim=(0, 4000), y_scale='log',)
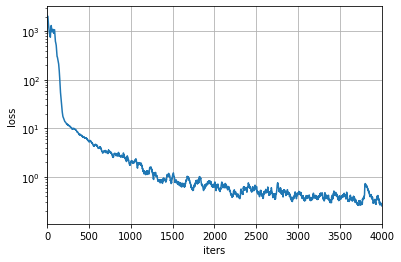
4000エポック学習させた後に表示したグラフは以下のようになりました。
横軸はエポック数、縦軸はloss値です。いい感じに学習できていそうです。
精度確認
以下のコマンドで検証画像についてラベルごとの認識精度を確認することができます。
# 実行形式 darknet detector map <.data> <.cfg> <weight> !./darknet detector map datasets.data yolov3-voc.cfg /content/darknet/backup/yolov3-voc_4000.weights
コマンドを実行するとクラスラベルごとの検出結果や、IoU, mAPといった物体検出の精度の値を確認することができます。
| TP (True Positive) | ラベルを正しく検出した数 |
| FP (False Positive) | ラベルの誤検出数 |
| Precision(適合率) | 予測した物体のうち正しく検出できた割合 |
| Recall(再現率) | すべての物体のうち正しく検出できた割合 |
| F1-Score(F値) | 適合率と再現率の調和平均 |
| Average IoU | IoUの平均値。IoUはラベルが存在すると予測した領域のうち、実際にラベルが存在している領域がどの程度かを表す指標。 |
| AP(Average Precision) | N個目のラベルを検出した時点での適合率の平均値 |
| Mean Average Precision(mAP) | 全画像のAPの平均値 |
各指標は予測結果の IoU が IoU threshold の値を超えたラベルを正解したとみなして計算を行います。IoU threshold の値は –iou_thresh オプションを指定してコマンドを実行すると変更できます。値を上げればより厳しい基準で評価することができます。
# iou threshold の値を変更 !./darknet detector map datasets.data yolov3-voc.cfg /content/darknet/backup/yolov3-voc_4000.weights –iou_thresh 0.7
今回はオプションを指定せず、4000回学習したweightファイルで評価を行ったところ、以下のような結果になりました。
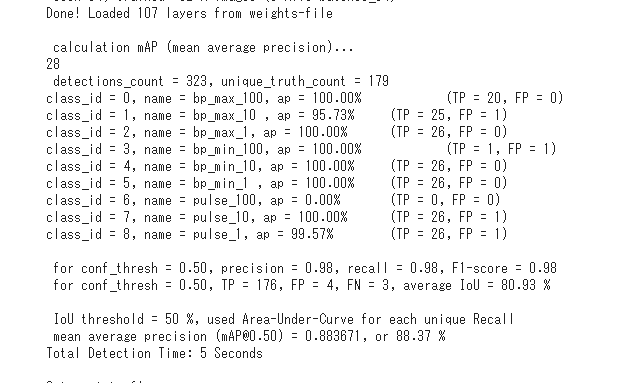
ほぼ正しく検出できていますが、class6 (脈拍3桁目)が0%になっています…。原因を調べたところ、学習データに脈拍3桁目が表示されているデータが存在していなかったためであることが判りました。
弊社メンバーには脈拍の高い人が少なく、データ作成の際に脈拍3桁目が表示された画像がすべて検証データに含まれてしまっていたため、モデルに脈拍3桁目の検出を学習させることができていませんでした。
データ作成時は、学習データと検証データの作成の仕方に十分注意する必要があるということですね。
テスト画像で物体検出
本当に学習できているか確認するため、未知の画像で物体検出を行い、結果を表示してみます。
検出は以下のコマンドで実行できます。
# 検出実行 # コマンド形式: darknet detector test <.data> <.cfg> <weight> <image> !./darknet detector test datasets.data yolov3-voc.cfg backup/yolov3-voc_last.weights /content/test.jpg
コマンドを実行すると darknet フォルダに predictions.jpg という名前で検出結果が出力されます。テスト用に撮影した画像をアップロードし、4000回学習させたweightファイルで検出を実行したところ、predictions.jpg は以下のようになりました。

ラベル付けした箇所の数値を正しく検出してくれました!
検証結果で0%だった脈拍3桁目が表示された画像はどうでしょうか?

脈拍3桁目はpulse_1(脈拍1桁目)として認識されており、検出に失敗しています。また、最低血圧の3桁目も2重に認識されています。より正確な検出をおこなうためには、さらに学習データを追加する必要がありそうです。
まとめ
物体検出に取り組んだのは初めてでしたが、一番大変だったのはデータ作成でした。特にアノテーション作業はひたすらに辛かったです。もうやりたくない…笑
しかし自分で手を動かすこと学べることや気付きも多く、勉強になりました。書籍やWeb上の解説を読むだけでは気付かないことも学べるため、興味のある方はぜひチャレンジしてみてください。