







*本記事は旧TechblogからCOLORSに統合した記事です。
目次
- 自己紹介
- やったこと
- 物体検出とは?
- YOLOv3
- 学習データの作成
- アノテーション
- YOLOv3 の学習
- Darknet設定ファイルの準備
自己紹介
はじめまして。株式会社エイアイ・フィールドのK.Tと申します。
前職ではソフトウェアエンジニアとして5年間パッケージソフト開発の仕事をしていました。
現在は機械学習、ディープラーニングを用いたレコメンドエンジンの開発に携わっています。
今回は Google Colaboratory を用いて、ディープラーニングによる物体検出モデル(YOLOv3)の作成に挑戦したので、紹介したいと思います。
やったこと
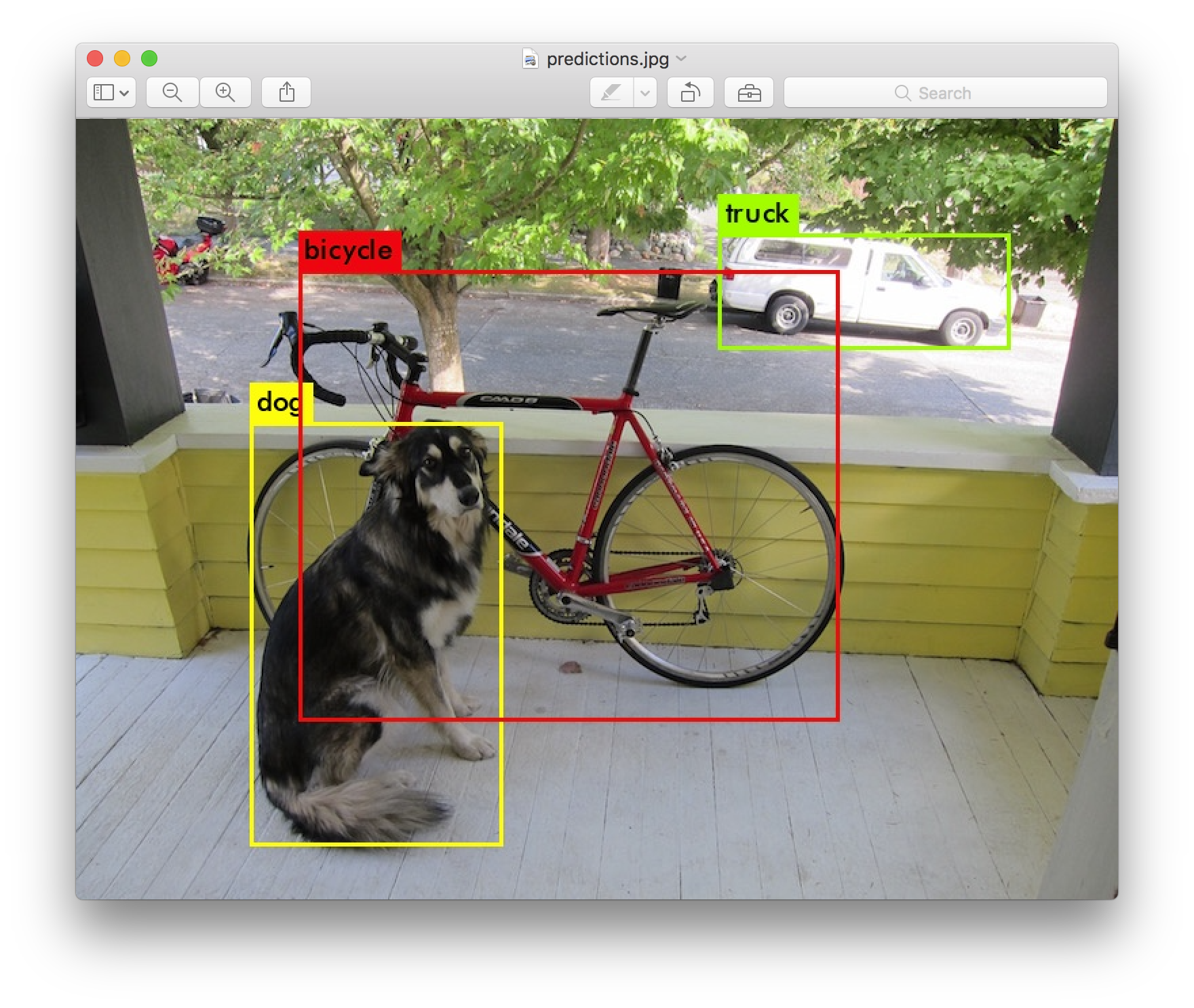
物体検出を行うディープラーニングデルを作成し、以下のようなスマホで撮影した血圧計の写真から、血圧(最高、最低)と脈拍の数値の位置を検出し、結果を下図のように表示してみました。

人が見れば一目超然ですが、ディープラーニングで同じことを行うと、どのような流れになるか知っていただければと思います。
物体検出とは?
物体検出とは、画像から検出したい物体の位置とそのカテゴリーを予測することです。コンピュータビジョンの1分野として研究されており、ここ数年はディープラーニングの登場で急速に進化しています。
YOLOv3
今回はディープラーニングの物体検出アルゴリズムの1つである YOLOv3 を使用して物体検出をしてみます。YOLOv3 は 2018 年に Joseph Redmon 氏によって発表された物体検出アルゴリズムです。高速な物体検出が可能です。詳しい情報を知りたい方は、以下の公式サイトと論文をご覧ください。
YOLOの公式サイト(by Joseph Redmon):https://pjreddie.com/darknet/yolo/
論文:https://arxiv.org/abs/1804.02767
今回は画像から最高血圧、最低血圧、脈拍の各桁の数値を検出してみます。物体検出モデルに写真(下図左)を読み込ませ、下右図のように各数値の位置を特定することが目標です。

学習データの作成
まずはモデルの学習データとなる画像を用意します。血圧計の測定結果のスマホ写真を200枚ほど撮影しました。撮影の仕方は特に定めず、液晶に近づけたり、遠くから撮影した写真を用意してみました。

上の画像は実際に撮影した写真の一部です(血圧計のメーカー名はぼかしてあります)。1回血圧を測定して写真を撮るのに1分程度の時間がかかり、1人では大変だったので、撮影時は社内のメンバーにも手伝ってもらいました。それでもかなり大変でしたが…。笑
撮影した写真は訓練用(train_img)と検証用(valid_img)で別のフォルダに分け、作業用PC内に格納しておきます。画像数の割合は訓練用:検証用 = 8:2 としました。

アノテーション
撮影が終わったら、撮影した各画像にアノテーションを行います。
アノテーションとはテキストや音声や画像等のデータにタグ付けを行うことです。アノテーションを行ったデータを学習(教師)データとして使用します。今回は各画像に対して「検出する物体の位置」と「カテゴリ」のラベル付けを行いました。画像内の位置座標とその数値が最高血圧、最低血圧、脈拍の何桁目の数値に対応するか、という情報を付加していきます。撮影した画像と、画像のアノテーション情報のデータが物体検出モデルの学習データとなります。 アノテーション作業は以下の環境で行いました。 Windows10 Pro 64bit (Anaconda インストール済み) あらかじめ Anaconda をインストールし、Python を使用できるようにしています。Anaconda のインストーラは以下のページからダウンロードできます。https://www.anaconda.com/distribution/#download
アノテーションには labelImg というフリーのアノテーションツールを用います。 まず以下公式のページにアクセスし、Clone or download -> Download ZIP をクリックして本体 zipファイルをダウンロードします。
解凍したら labelimg-masater 内の data フォルダに入っている predifined_classes.txt を開きます。このファイルには識別したいカテゴリの名前を記述します。デフォルトの記述を削除し、識別させたいカテゴリの名前を1行に1つずつ記述していきます。
今回は以下の9つのカテゴリ名を記述しました。

続いて Anaconda prompt を開き以下のコマンドで pyqt5 をインストールします。
conda install pyqt=5
こちらは labelImg の起動に必要になります。環境を汚したくない方は適宜仮想環境を作成して下さい。インストールが終わったら Anaconda prompt 上で labelimg-master フォルダに移動し、以下コマンドを順に実行します。
pyrcc5 -o libs\resources.py resources.qrc python labelImg.py
インストールが成功していれば、labelImg が起動し、ツール画面が表示されます。
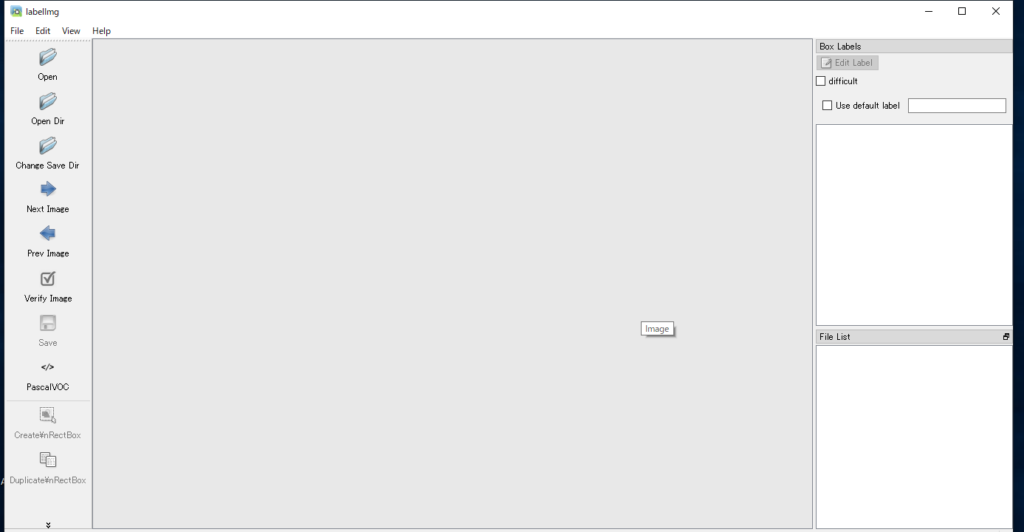
無事ツールを起動できたら、用意した画像にアノテーションを行います。
まず左のメニューの Pascal VOC をクリックし、 YOLO に変更します。これはアノテーションファイルの保存形式を YOLO モデルで使える形式で保存するという設定になります。これを忘れてアノテーションしてしまうと作業がやり直しになるので要注意です。
続いて左のメニューから Open Dir をクリックし、画像を格納したフォルダを指定します。フォルダ内の画像が読み込まれ、画面に表示されます。

次にアノテーションファイルの保存先を指定します。Change Save Dir をクリックし、ファイルダイアログから Open Dir で読み込んだ画像フォルダを指定します。これでアノテーションファイル保存時に自動的に画像フォルダ内に保存されるようになります。
ここまで済んだらようやくアノテーション開始です。Wキーを押して矩形選択モードに変更し、検出したい物体の領域をドラッグして矩形で囲むと、predefined_classes.txt に記述したカテゴリ名の一覧が表示されるので、囲んだ物体に対応するカテゴリ(下図の場合はbp_max_100)を選択しOKを押します。囲む領域が小さい場合は Ctrl + マウスホイール操作で画像の拡大、縮小が可能です。

カテゴリを選択するとEdit label に選択したカテゴリ名が登録され、ラベル付けができます。
同様に他のカテゴリに対してもラベル付けし、画像内のすべてのカテゴリのラベル付けが終わったら Ctrl+S キーで内容を保存します。すると画像フォルダ内にラベル付けした画像と同名の .txt ファイルが保存されます。
これで一つの画像に対するアノテーションが完了です。 Next/Prev Image ボタンで画像を変更し、残りの画像についてもアノテーションを行います。すべての学習用画像についてアノテーションを行ったら、Open Dir, Change Save Dir で検証用フォルダを読み込み、検証用の画像に関して同様にアノテーションを行います。
地味で根気のいる作業ですが、物体検出モデルの精度に関わる重要な作業なので、なるべく数字をピッタリと囲むような矩形を作成し、丁寧に行なっていきます。
訓練用、検証用の全ての画像のアノテーションを行なったら、train_img, valid_img フォルダをそれぞれ zipファイルに圧縮しておきます。
YOLOv3 の学習
Darknet設定ファイルの準備
アノテーションを終えたらモデルの学習を行います。YOLOv3 の学習にはDarknet というフレームワークを使用します。Darknet は YOLOv3 の製作者によって開発されたフレームワークで、自分でソースコードを書かずともYOLOv3 の学習を行うことができます。
今回はAlexeyAB 氏によって公開されているDarknet を使用し、Google Colaboratory 上で動作させて学習を行います。Darknet の公開先は以下です。https://github.com/AlexeyAB/darknet
Darknet の学習を行うには以下のファイルを準備する必要があります。- train.txt
- valid.txt
- classes.txt
- yolov3-voc.cfg
- datasets.data
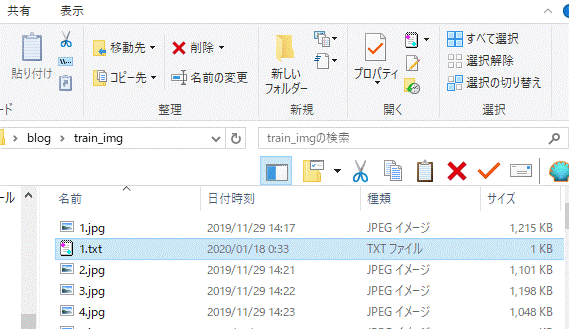
1.train.txt
darknetの学習に使用する画像ファイルのパスを記述します。今回はtrain_img フォルダ内の画像のパスを記述することになります。パスはtrain.txtを配置する場所からの相対パスでOKです。今回は train_img フォルダと同じ階層に配置するので、下図のように記述しました。

2.valid.txt
1と同様に、valid.img フォルダ内の画像パスを記述します。3.classes.txt
識別するラベル名の一覧を記述します。アノテーション時に作成したpredefined_classes.txt ファイルの中身をそのままコピーすればOKです。
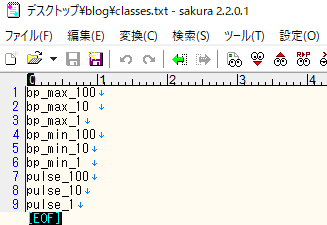
4.yolov3-voc.cfg
YOLOv3 のモデル学習時のパラメータを設定するファイルです。まずはDarknetリポジトリの以下のページから cfg/yolov3-voc.cfg の中身をコピーして貼り付けます。https://github.com/AlexeyAB/darknet/blob/master/cfg/yolov3-voc.cfg
コピーした設定をベースに、リポジトリのHow to train (to detect your custom objects)を参考に設定を変更していきます。今回は以下のように設定を行いました。

[yolo] レイヤの設定はファイル内に該当箇所が3箇所あるので、すべての箇所で同じ設定を行います。また、batch および subdivisions の値がリポジトリの設定と異なりますが、今回はリポジトリそのままの設定だと学習中にメモリエラーになってしまったので、小さめの値を設定しています。
5 .datsets.data
識別クラス数、train,validファイルのパス、バックアップ用フォルダのパスを指定するファイルです。以下のように設定しました。
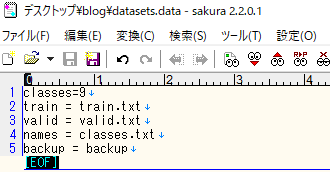
以上で YOLOv3 の学習に必要なファイルが用意できました。後編では Google Colaboratory を使用してモデルの学習を行っていきます!



